

Last time we looked at the tools and services that could be used to stress test our Azure-based application. This will be a direct continuation of that post, so if you haven't read part 1 you can find it here.
I concluded in my previous post that I would be using Loadster (not to be confused with Loader, a similar service) as the tool of choice. Loadster is a SaaS performance testing solution. It has a pay-as-you-go billing possibility, which is surprisingly not very common with these kinds of services. It also seems like a fairly mature software with features like user management and at least some support for CI/CD, since realistically we would like to integrate the tests into our DevOps at some point.
We won't be deep-diving into all the features of Loadster, but link to the official documentation here.
About pricing
Most services offer billing options that are subscription-based or they just ask you to "get a quote" outright. The subscriptions are usually priced upward of hundreds of dollars a month and the quotes are probably geared towards enterprises with an enterprise price. Not that consuming Loadster as you go is cheap either, but this is probably one of the most affordable ways to run our test with the power we need.
It's not surprising that the industry standard seems to be to hire specialized companies/consultants instead of performance testing internally. It's a lot of work and requires extensive knowledge about the subject. It reminds me a bit of security and pen-testing, except I would argue that performance testing is a more niche area. At least when done seriously and with expertise. This considered I'm starting to understand why many of the SaaS services don't even bother with clear pricing tiers. I wouldn't be surprised if extensive support and consultancy are be baked into many of these offers.
Get on with it
Let's start stress testing. Unlike a load test, the objective of a stress test is to find the breaking point of our application. I'd like to make the environment we are testing at least fairly realistic, something like a small to medium-sized production environment, so that's how the resources and baseline response are structured. The tests are also designed to represent a real-world situation where users ramp up over time instead of coming all in immediately. The target is a single endpoint that could be something like a small calculator utility. Our first test should be quite easy for Azure to pass:
Test 1
Specs:
- Azure App Service that simulates load and returns 2000 generated guids per request
- Runs on S1 App Service plan (lowest production plan)
- Baseline response without load finishes in 100ms and returns ~50kb of data
- Requesting with 300 bots distributed across 3 regions
- Gradual ramp up from 0 seconds with 0 bots -> 8 minutes with 300 bots -> runs for 2 minutes and ramps down in the end
- Autoscale configured to scale up when at least 50% CPU is used (up to 10 instances)
I will be adding a link for each test for the full Loadster results. I recommend checking those out yourself since they contain interesting data in a nicely presented format. This article is already going to be quite long, so I won't be covering every single data point in those reports. I will also put the cost of every test in the results sections.
Results
Our API handled this test well with 0 errors. Let's take a look at the response times:
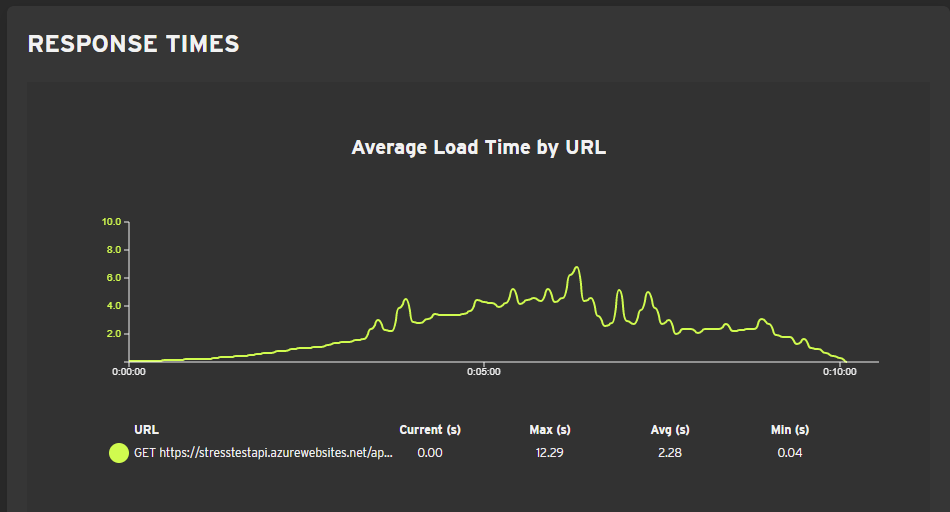
App Service autoscaled 2 times, first at the 6-minute mark and then at the very end which didn't have much impact on the results. The maximum individual response time was 12 seconds, but the max average was only about 6 seconds. Could be lower, but it's not bad considering this load was already pretty heavy with ~4000 requests per minute.
Test 1 cost: 5,05€
Let's try doubling the bots and see what happens.
Test 2
Specs:
- Azure App Service that simulates load and returns 2000 generated guids per request
- Runs on S1 App Service plan (lowest production plan)
- Baseline response without load finishes in 100ms and returns ~50kb of data
- Requesting with 600 bots distributed across 3 regions
- Gradual ramp up from 0 seconds with 0 bots -> 8 minutes with 600 bots -> runs for 2 minutes and ramps down in the end
- Autoscale configured to scale up when at least 50% CPU is used (up to 10 instances)
Results
0 errors again. Response times:
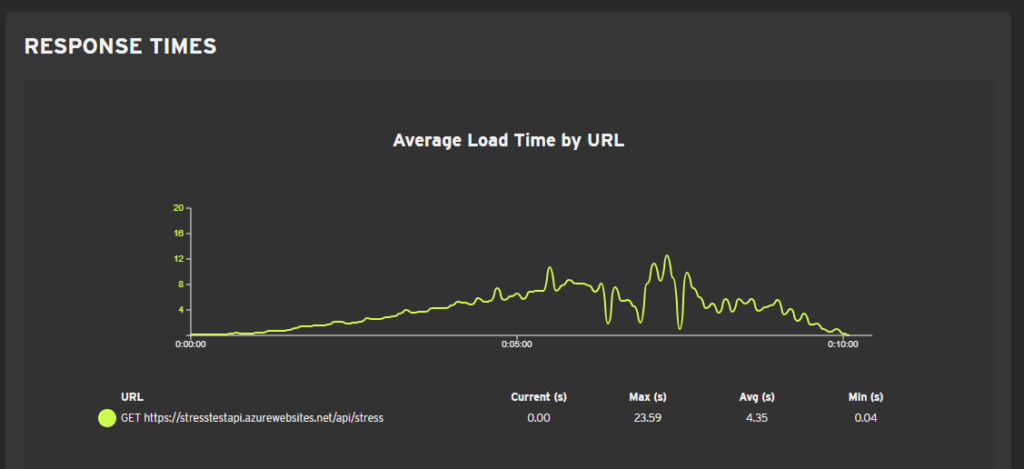
Maybe this was predictable, but response times were almost exactly doubled. Even 12 seconds maximum average is still not unbearable. Requests per minute did not increase much. This is because when the response times increase the bots can't make more requests until they get a response or an error. Autoscale fired 3 times.
Test 2 cost: 10,1€
I'd like to get some errors going, so I'm going to triple the simulated compute in the API and run this test again.
Test 3
Specs:
- Azure App Service that simulates load and returns 2000 generated guids per request
- Runs on S1 App Service plan (lowest production plan)
- Baseline response without load finishes in 160ms and returns ~50kb of data
- Requesting with 600 bots distributed across 3 regions
- Gradual ramp up from 0 seconds with 0 bots -> 8 minutes with 600 bots -> runs for 2 minutes and ramps down in the end
- Autoscale configured to scale up when at least 50% CPU is used (up to 10 instances)
Results
0 errors. Response times:
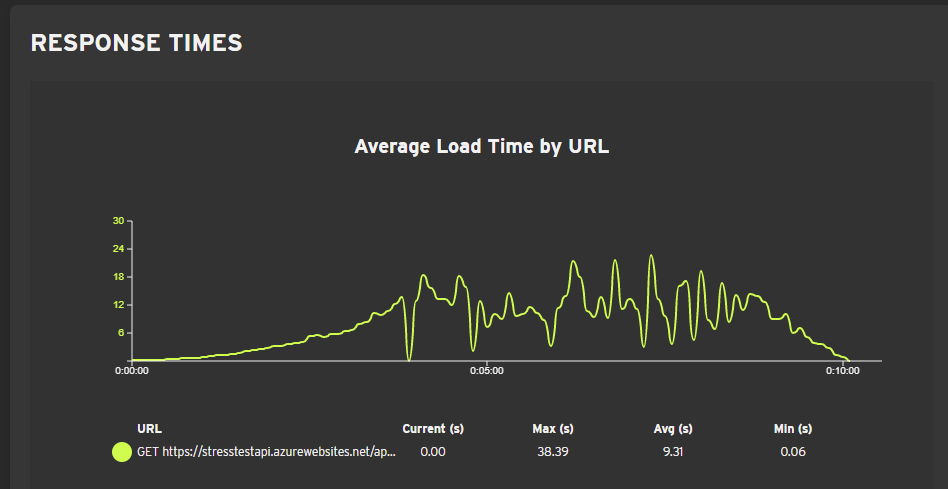
Some weird stuff started happening here. The graph shows that sometimes response times were 0 under load. I assume that these were moments when the API was processing and no responses were returned. The maximum average response time went to about 20 seconds and the maximum individual response time went to 38 seconds. Requests per minute actually went down. Autoscale fired 3 times.
Test 3 cost: 10,1€
We still have Loadster credits left, so let's use all that is left and tweak the API a little bit with 10 times simulated CPU and 10000 returned guides.
Test 4
Specs:
- Azure App Service that simulates load and returns 10000 generated guids per request
- Runs on S1 App Service plan (lowest production plan)
- Baseline response without load finishes in 250ms and returns ~270kb of data
- Requesting with 1800 bots distributed across 3 regions
- Gradual ramp up from 0 seconds with 0 bots -> 8 minutes with 1800 bots -> runs for 2 minutes and ramps down in the end
- Autoscale configured to scale up when at least 50% CPU is used (up to 10 instances)
Results
Okay, that did the trick: 19269 socket timeout errors. The graph:
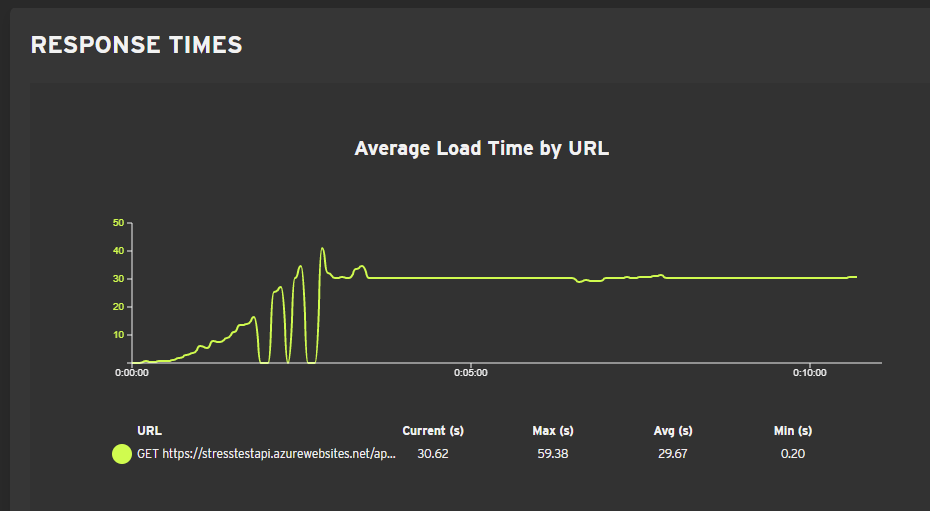
That was pretty rough. The bots get about 900 responses until the average response time flatlines. I'm not entirely sure how to read that, except that suddenly nothing is happening. The first autoscale at 6 minutes doesn't help at all, just creates a little wobble and some successful responses until the graph flatlines again. The second autoscale came too late and didn't affect the test. Autoscale went on to fire 2 more times, but that scaling happened outside the 10-minute window of our test. On a nice note, the API was back to normal in about 10 minutes without me having to do anything.
Test 4 cost: 30,3€
Analyzing the results
Turns out it is quite difficult to outright DDoS App Service if autoscale is configured at least decently. Even when response times grow, usually the requests just get queued and will be answered eventually. But maybe that's not the point, since the system can't exactly be considered to be working if you have to wait forever for a response. It's also important to remember that even long response times may be acceptable. It all depends on your SLA.
Thoughts about viability
Performance testing, in my opinion, can't be classified as something "everybody should do". But it will always be useful. As mentioned before, even with a simple API, you should always be aware of response times under load, even if no actual timeouts happen. It's also quite nice to have the exact parameters, graphs, and a huge amount of additional data to see how your environment behaves as load increases. If you ever need to configure autoscale to optimally fit traffic, these metrics become almost essential.
Another scenario where performance testing is very useful is testing dependencies that get added to the project after the initial solution has been in production for a while. Example: You have a production API that has served its purpose very well by just computing data and serving the results back to the clients. It has passed your performance tests easily. Suddenly, the business wants to start persisting some of that processed data. Under small load the connected new dependency, let's say Azure SQL, doesn't present any problems and is working fine.
However, after running your performance tests in pre-production, you find that SQL exceptions start happening and the API is choking. You have just pre-emptively discovered a bottleneck caused by a new dependency. This kind of disaster prevention is gold for the business. The product owner might not have even noticed, but when everything is running smoothly after every deployment, it presents a pretty nice feeling about the team and the project. You can contrast that emotion with the one we get when production goes down after x amount of time since the latest changes were made.
Conclusion
Performance testing is a surprisingly large area that requires a lot of thought before you can even launch a single serious test. It is expensive and work-intensive, and an argument could be made that many (cloud) applications don't need it. However, in a project that keeps growing and growing, performance testing becomes something that can save everybody in the business a lot of pain. Can you pinpoint the moment where the system will break a critical SLA? Knowing the answer to that single question will help you plan for contingencies and mitigate error situations.
Read about our DevOps offering and learn how cloud adoption is changing the way how small and big businesses are doing software development and operations.


