
Ever had to try and figure out what a colleague who left the company a year ago wrote down about a project you're supposed to take over? Every day, employees in enterprises big and small squander countless work-hours searching for internal information they need in their daily work. This information is most often hidden in documents and files that are hard to find, forgotten in some obscure corner of a document management system. To tackle this, organizations need to find innovative ways to accelerate access to their knowledge resources. To this end we at Zure decided to build something that uses natural language and smart searching to allow people to be more efficient and knowledgeable at work, in a secure and governable fashion. In this blog post, we share what we encountered and learned on the way.
This blog post has been co-created by Data Engineer Pontus Mauno and Azure Developer / Architect Janne Pasanen.
Starting point
Having decided to use the Microsoft Cognitive Services stack (more specifically Azure OpenAI Service and Cognitive Search), our goal was to improve the bare-bones Microsoft architecture to an enterprise-grade one with sturdy security and governance features. Thanks to our colleague we already had an up-and-running Azure OpenAI Service with GPT-4 and Cognitive Search available. Therefore we started with setting up the Retrieval Augmented Generation (RAG) pattern published by Microsoft last spring and went on from that, adding more capabilities and enterprise features as we went along.
For the UI we initially chose Teams to be able to build on top of our existing ZureBot, an Azure OpenAI and GPT-4 powered chatbot assistant running in Teams. This also allowed us to provide a familiar environment to users via an existing solution that we expanded with new capabilities. Further down the road we also set up a Web UI (first also based on the MS RAG pattern example) to provide a more customizable knowledge search experience that was not to be found in Teams, but more on that later.
In short, the tech stack we decided on was:
- Azure OpenAI Service
- Cognitive Search
- Azure Bot Service
- Azure Data Lake
- App Service
- Azure Functions
- Event Grid
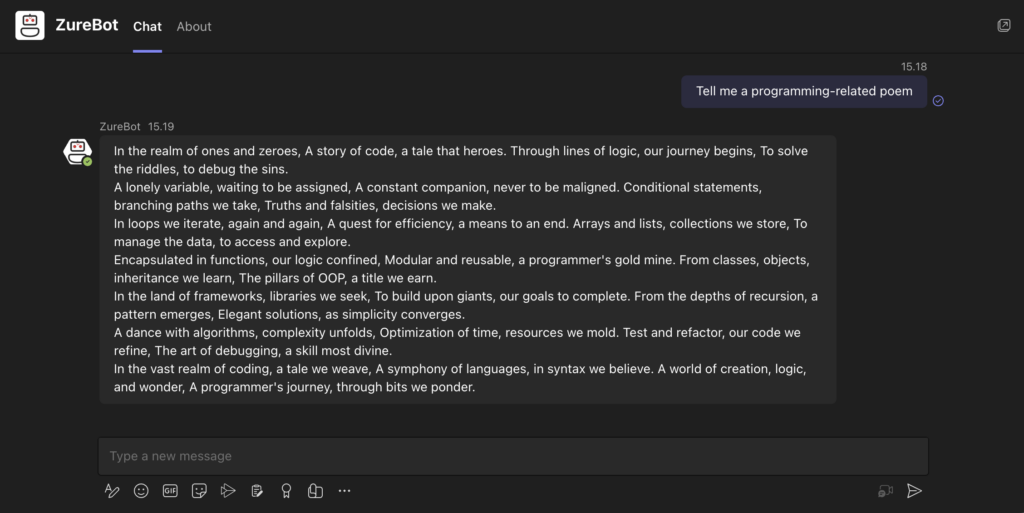
First iterations
Having decided on the tech stack and having the building blocks for the solution itself, we set on connecting the first internal data sources to enrich the chatbot with. The most obvious first candidate was the SharePoint-based intranet with its plethora of guides and information for employees. While integrating anything with SharePoint is famously painful and unintuitive, this was eventually done during a dark night after which the SharePoint pages were retrieved and indexed to our Cognitive Search and the ZureBot was happily answering questions about everything in our intranet, to everyone. However, at this point the retrieved data was stale, open for everyone who had access to Teams and required a new indexing run to update it.
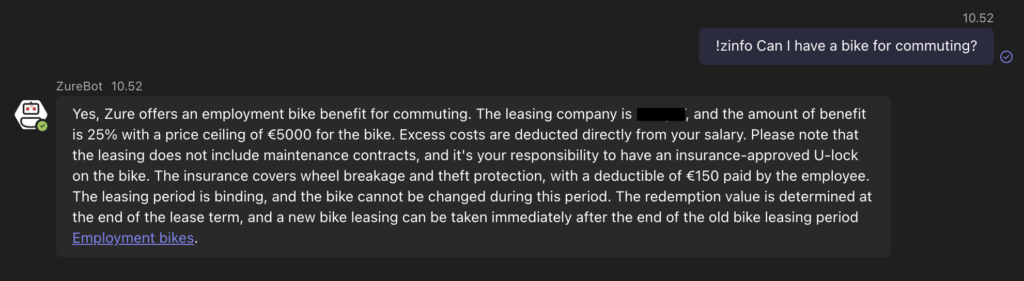
The next step was to implement authentication to be able to authorize live access to sources with private data. This feature was needed for our following test that involved integrating the search functionality of our solution directly with SharePoint files. The first version of this Teams-integrated SharePoint search was simply a command to search and retrieve a list of document URLs. This was much improved with the next version that was able to feed SharePoint document contents to the GPT-4 model that could then answer questions based on the document contents.
However, this version quickly ran into the issue of token limits, as many documents exceeded the token limit of what the model could handle. The solution was to split the documents to smaller chunks while trying to maintain coherence within the chunks. This was a continuous balancing act and depended heavily on the type of content being indexed, for example Word files behave very differently from PowerPoint files when split.
Web UI & improvements
Having built the initial solution as a Teams bot, we wanted to streamline and broaden the user experience by also providing a Web UI. This was initially based on the MS example and allowed us to provide a more configurable development experience as well as present a more transparent view to the workings of the AI models.
On the backend side, we started to work with the actual raison d’être of the whole Enterprise Search, custom company data. We started uploading a wide variety of files and documents not found directly in SharePoint to our data lake to provide a source-agnostic storage for the documents. These documents were then indexed in Cognitive Search and used as sources for a number of cases, for example matching projects and developers with suitable experience and tech stacks.
This addition of different kinds of data from varied sources also necessitated the development of more granular access control to make sure only people with authorization could access a given document or file. For this purpose the hierarchical folder structures as well as access control lists combined with Azure AD groups were found sufficient. To handle changes in the folder contents the blob events were also tracked and the indexes rebuilt as needed.
The final building block we added was the capability to access and index Office 365 data such as Teams chats, emails, calendar events and all such things via the Graph API. This capability obviously requires the most planning and oversight due to the potentially sensitive data accessed, even if permissions and authorization are managed normally via Azure AD. However, we wanted to test how thoroughly we could index and reach company data to maximize the benefits of the Enterprise Search to users.
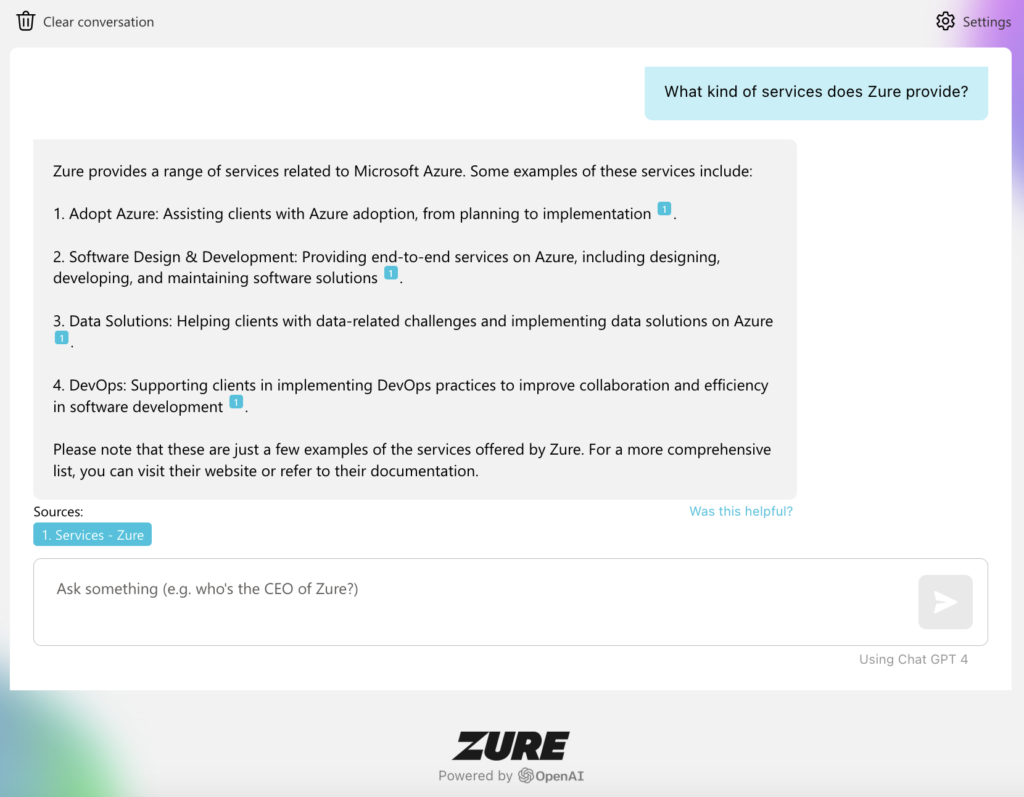
With these features, we had an alpha version of the Zure Enterprise Search that was (and is) able to
- Provide a vanilla GPT-4 chat UI for internal company usage
- Search large amounts of files and documents with natural language
- Answer questions with information from any given source that can be indexed
- Gives sources and links on which the answers are based
Challenges
While building this solution we also naturally ran into challenges related to the novel tech and architecture. Most of these were solvable but some issues require tradeoffs or (in the case of LLMs) necessitate accepting some variance in the output.
Tokens
The most obvious limitation applying to all LLMs (Large Language Models) is the token limit. While the token limits have gone up in Azure OpenAI Service since last spring (from 4k to 32k) they still limit the amount of context the model can handle when formulating an answer. Furthermore, every token incurs billing and adds latency which naturally motivates us to minimize their usage. Costs have to be accounted for especially with GPT-4 where maxed inputs/outputs with 32k tokens incur several euros of costs.
Searches
Another interesting topic we researched was the tradeoff between using the classic "simple" search of Azure Cognitive Search and Semantic search (We've also worked with Vector search while that was in private preview but more on that in a separate blog post). While Semantic search often gave improved performance, it is not perfect either, works only in English and comes with a rather spicy pricing scheme that needs to be balanced against the gains. For the time being we settled for using the "simple" search combined with LLM-generated keywords that essentially mimicked the Semantic search functionality.
Translations
We also wanted to deliver as language-agnostic experience as possible to our users. However, we soon noticed that while LLMs generate good general language translations even with niche languages like Finnish, when the language gets technical the risk of mistranslations grow. It still often gets things right, but requires expertise and thought when checking the answers for correctness. To aid with this, the solution also returns sources to its answers.
Context and memory
As for making the interaction with Enterprise Search more "chatlike", we had to decide on how to manage the conversation context and "memory" for the LLM. Our initial solution was to keep the document-search in single-shot form with no memory of previous messages and to drop the oldest message after five messages when in vanilla chat mode. This obviously led to impossibility to iterate the searches "on the fly" and that document content and vanilla GPT chatting were not compatible. While our following iterations remedied these issues to provide one chat-like Q&A experience, managing memory especially with long and complex conversations remains a tradeoff between costs, performance and quality.
Costs
Managing and even tracking the costs of the solution was also at times challenging due to the (private) preview status of many of the components as well as the per-token billing of the LLMs. This meant that the way users prompt Enterprise Search is the biggest factor in the cost structure of such a solution and (like humans) is often unpredictable or random. Furthermore, the Cognitive Search can be a rather pricey building block to use depending on the configuration and service tier.
Performance
We found out that while the other parts of the Azure AI stack such as Cognitive Search are rather performant even with large source datasets, regardless of the service tier. On the other hand, the vanilla GPTs (especially 3.5 turbo) are rather quick with simpler tasks and smaller token counts, we experienced random exponential performance degradation with larger contexts. For example direct one-sentence dialogues with GPT-4 happen in the millisecond range but in worst cases complex contexts would take almost a minute to give an answer to. This is way too much for a tolerable user experience and we are apparently not the only ones experiencing such degradation, thus we are waiting for Microsoft's response to the matter.
Learnings & outcome
To wrap things up, what we have so far learned during the project:
- The concept of enterprise information retrieval does work and speeds up information searching significantly
- Integrating LLMs to other software is both very promising but also volatile.
- Managing costs requires vigilance, as almost all billing happens per action.
- Azure OpenAI performance is a black box, random user experience hurting degradations do happen
- While the simple Cognitive search is sufficient, Semantic and Vector searches show great promise (at a price).
- Optimizing conversation memory and context is an eternal balancing act.
- In general, working with bleeding edge and preview tech was often uncertain and based on trial/error.
Despite the hurdles of working with preview stuff, the feedback from developers working with LLM and AI tech has been positive in that it does indeed differ from "traditional" and deterministic software development. Furthermore, looking at the current Enterprise Search even with the technological limitations, we see great promise in the way enterprise information retrieval can be streamlined with solutions like this and have thus adopted this tool to our palette.

Let’s talk!
Want to learn more about adopting OpenAI into your business? Leave your contact information below and we’ll be in touch soon.
Explore the benefits of adopting Large Language Models into your business with Azure Open AI Service in this article.

