
As exciting as recent advances in the field of artificial intelligence are, they’re also fascinating challenges for quality assurance practices.
At Zure, we recently started building internally AI-based chatbot with a goal to create our internal “ChatGPT”. The goal was to leverage our company's own data to develop a chatbot that would help to find relevant information from a single place. Whether it was questions about marking holidays to HR system, instructions to book childcare for sick child or sending an invoice, the chatbot could assist you.
As we were starting the project, we started pondering how we could actually assure the quality? The chatbot was going to be deployed for the whole company and we had to make sure that performance was up to the task.
As there were generally very few experiences around testing AI-based chatbots, this started a journey to find out the best ways to test the application. With this blog, I want to share some of those learnings and experiences we confronted during the process.
For a more deep dive of the development process and technical choices made, be sure to check out excellent blog post wrote by Pontus and Janne here.
First Steps of the Testing Process
One of the first steps was to understand what we were actually testing. AI-based chatbots are fundamentally different from traditional software applications. You are only interacting with a chat interface which is a “black box”. There is little to no visibility to the system itself - you give an input and get an output as a result. They're also non-deterministic by nature - if you ask same question twice, it’s possible that answers are different.
Therefore, the “black box” and non-deterministic nature were challenges to tackle. How could we ensure that answers were correct and high quality, especially when responses could vary each time?
A crucial key to this is to have access to the source data, or already have a deep domain knowledge. In our case, we had our company data coming from SharePoint-based intranet and documents stored in Azure Data Lake.
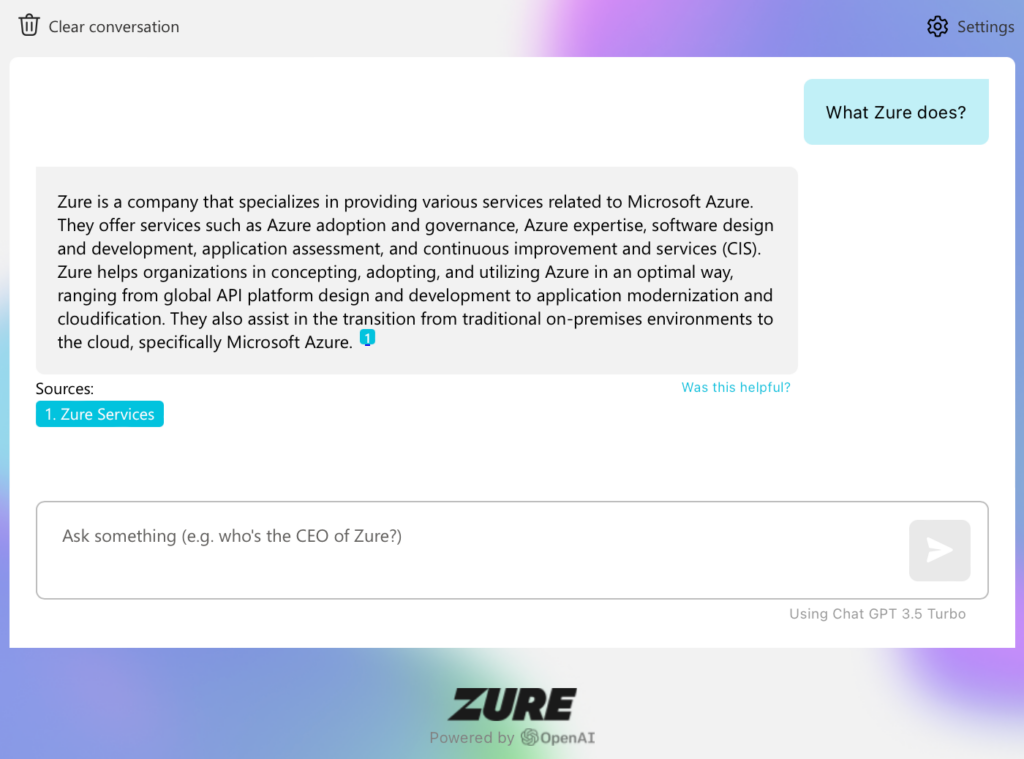
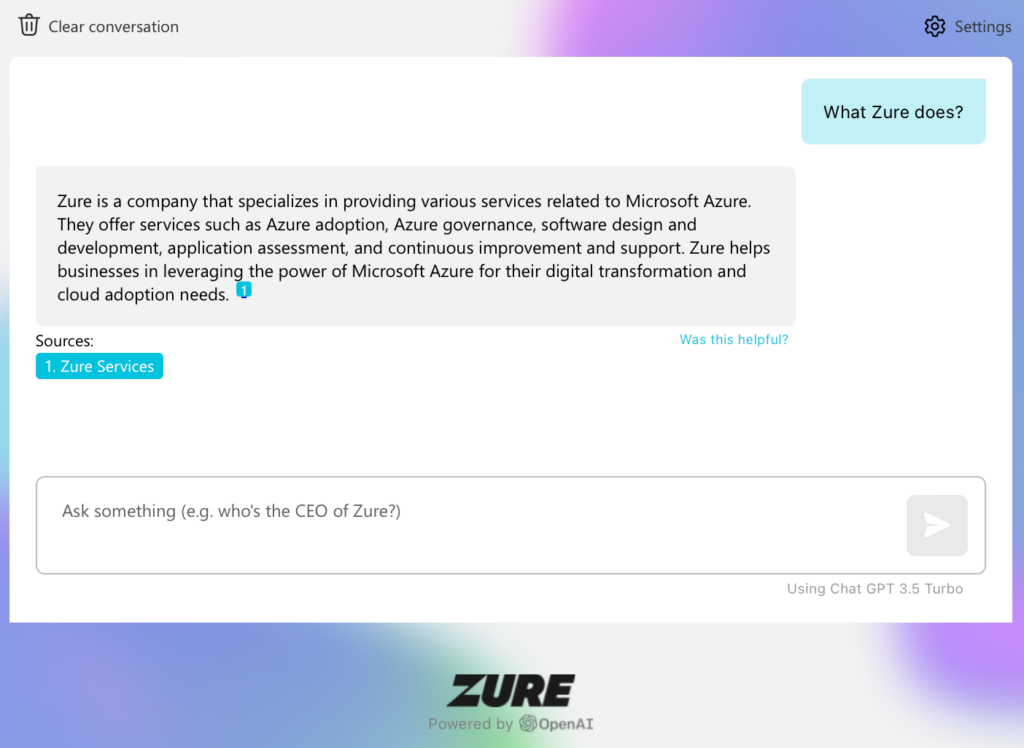
Creating a Test Plan
The source data provided a foundation for our test plan. Based on the data, different scenarios, questions and variations could be created and, of course, it acted as a source of truth.
The test plan played a pivotal role in the testing process. We crafted sets of questions and conversations as test cases and documented answers we got. As changes were made, it was extremely helpful to be able to come back to answers from previous test runs and monitor the quality of answers. The test plan served as our validation set; we asked same questions in each round and therefore could easily compare results.
Initially, the test plan was a rough framework. It’s been since constantly expanded as understanding of capabilities have been expanding. It doesn’t have to be perfect from the start - it’s better to get going and refine it as you go.
Designing Test Cases
There are endless possibilities for test cases when testing AI-based chatbots. However, as usual, keeping in mind what the actual end-user would do is a great starting point.
For instance, examine how well the system handles variations in writing, such as synonyms, sentence structures, and misspellings. In real-world usage, these are common, as rarely people write down perfectly nor match the exact words used in the source data. If the source data contains only term “sick leave”, how well the bot can answer questions with terms “leave of absence”, “illness leave” or just “ill”?
It was also informative to create cases about different kind of tasks and scenarios it would likely confront with real users and monitor performance on those. How well it can summarise employee handbook in few sentences, how it manages to answer questions asked in different language than the source or just how well it can follow the context of a longer conversation - just to mention some.
Even when relying heavily on the source data, it’s important not to be its servant. Use creativity and make up cases as you go - just as a real user would! This way you might reveal things you wouldn’t find by following a strict test plan.
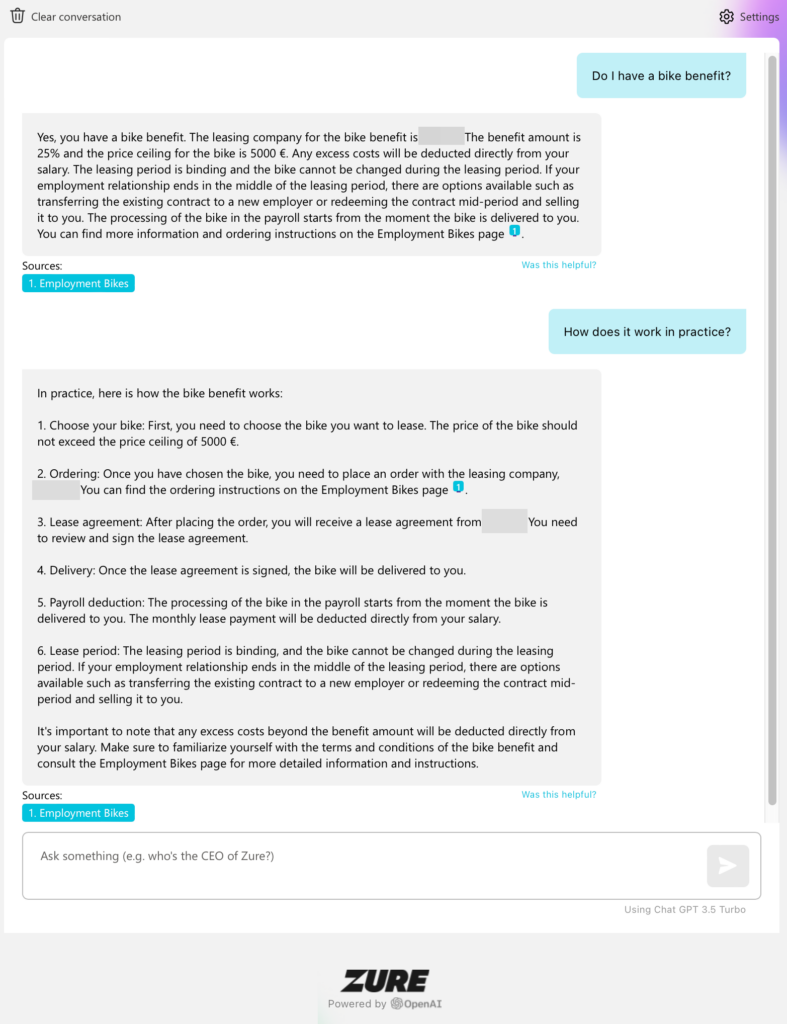
Data Sources and Types
Another interesting aspect found during the journey was different data sources and types. As mentioned, we had data in SharePoint and various of files in Azure Data Lake. There were different file types, including Word documents, PowerPoints and PDFs. Contents also varied a lot; some documents were lengthy, some were in English and some in Finnish.
By making own test cases for each type and case, we could monitor the quality of answers and assure that answers were correctly fetched from different sources and documents.
Additionally, it was extremely important to thoroughly examine source links in each test case. Source links must be accurately provided and direct the end-user to relevant information.
Concept of Red Teaming
Lastly, I would like to highlight the concept of red teaming. In short, this shifts the focus towards attempting to make the chatbot provide inaccurate information or perform actions it shouldn't.
For example, you can explore different methods to request restricted information or even challenge the chatbot to bypass its safety measures entirely through prompt injections.
Designing test cases by being aware of known behaviours helps a lot. AI-based chatbots may exhibit behaviours such as hallucinating responses, avoiding answers (lack of confidence), or providing incomplete information by missing exceptions. Keep an eye out for these behaviours and actively test for them.
In Summary
To recap, here are the key learnings:
- Gather understating about the system under test
- Investigate the source data
- Create a test plan and test cases
- Variations: synonyms, misspellings, sentence structures
- Tasks: summaries, translations, tasks, lists
- Data sources: own tests for each, cross-checking
- File types: PDFs, PowerPoints, Words
- Contents of documents: different languages, lengthy documents
- Adversarial cases: unauthorised information and access, hallucinations, lack of confidence
- Pay special attention to source links and known behaviours of AI-based chatbots
- Document questions and answers to the test plan for future reference
Closing Thoughts
While there's much more to explore beyond the points discussed here, these were just some insights I wanted to highlight at this early stage. Each test run gives fresh ideas to how to evaluate the chatbot.
As AI-based applications continue gain popularity, new ways to test them will also be needed. New tools, techniques and even possibilities to automate parts of the process, will likely emerge in near future.
We are in the early innings of this exciting journey and there's much more to discover!
Want to learn more about AI?
Check out how we help turbocharge access to enterprise knowledge with Azure OpenAI and tips and possibilities on adopting OpenAI into your business.

