

By now, I guess you have heard about the latest shiny object Microsoft released at the end of May this year. Microsoft Fabric is, according to Microsoft, an all-in-one analytics solution for enterprises that covers everything from data retrieval to data visualization and everything in between. The idea is to bring together individual analytic tools and services and provide a unified analytics experience. Okay, so now some might think that I described Azure Synapse Analytics... Fair enough, Synapse had the same idea and the good parts from Azure Synapse Analytics can be found in Microsoft Fabric also. But it also has new unique features that were missing in Azure Synapse.
We here at Zure have been working with Microsoft Fabric since its preview release. In this blog, I'll shed some light on the core features that Fabric is built upon and share the experience we have had during this half-year timespan. Note as of writing this blog, Microsoft Fabric is still in public preview.
OneLake - Common Storage Layer
The concept of a data lake is quite simple. You have one storage that holds all the data in different formats, and then the data should be easily obtainable and managed. However, the reality can be entirely different. It's likely that there are several different data lakes siloed up to serve some specific task. Setting up a transparent and easy-to-use logical layer on top of that can be cumbersome. To tackle this complex problem, Microsoft provides OneLake - an organization-wide logical data lake to fulfill the one data lake promise. The main idea is that when working with Microsoft Fabric, regardless of who is working with any sort of data, the underlying system presents as one big storage. Bold statements, but actually, the initial real-life lessons back this up.
What´s in the lake?
Beneath the logical layer, OneLake is formed of multiple Azure Data Lake Storage resources. A thing of beauty is that platform admins don't need to maintain or manage these resources. They are provisioned automatically and enable the unified file format (Delta Parquet) for all the data located in OneLake. This, together with the shortcut feature, brings a lot more control for data owners. Shortcuts are logical pointers to obtain a certain dataset from a different lakehouse or an outside data lake (Azure storage account or Amazon S3). Data is managed and governed once in the original location and can be exploited in other lakehouse items without worrying about data management and duplication again and again in various places.
The representation of the storage object in Microsoft Fabric is the lakehouse item. The lakehouse is split into two different sections. The Files section can have any kind of data stored and is more or less the same as the Blob service in Azure storage accounts. The second section is called Tables, and this one holds the unified Delta tables which can be used across different workloads inside Microsoft Fabric. What it means is that for example if you store and manage data with the Notebooks and Spark engine, the same data and tables can be accessed with warehouse and SQL syntax instantly from the same data location.
Compute Engines
The decoupling of storage and computing inside Microsoft Fabric has some unique features attached. The shared storage and Delta Parquet unified file format establish the base of Microsoft Fabric, and on top of this, there are multiple different compute loads for different use cases. Below you can find some of them. Don´t mind the ambiguous naming, they are indeed Microsoft Fabric items
- Data Factory, which is the next evolution of Synapse Pipelines or Azure Data Factory.
- Synapse Data Engineering, aka Spark-compute platform for developers to create large-scale data processing with a code-first experience.
- Synapse Data Warehousing, which is a T-SQL engine enabling to query and process the data in a structured manner.

Depending on the need and the problem that needs to be solved, a specific tool is chosen to resolve the situation. The more intriguing aspect is that regardless of which tool is used, the data is stored straight in OneLake in the same format. This means that the same data is accessible easily across these different workloads. This simplifies and decreases data movement inside different phases when the same copy of data is accessible from start to finish. The other benefit that this workload evolution in Microsoft Fabric brings is the SaaSification part. The underlying resource management is outsourced to Microsoft. This, of course, is a double-edged sword. This eases the platform management part and gives more time to focus on data-specific solutions. On the other hand, this also narrows down control of these resources and hands it over to the product. Mostly this is fine, but in some cases, it might cause headaches. Like in all SaaS products, it is this constant balancing between control and ease of use.
Fabric capacity FTW
The underlying power for all items in Microsoft Fabric is the universal computing capacities. Fabric capacity is the collection of dedicated resources to be shared between selected items in Fabric. These capacities are served in Stock Keeping Units (SKU) which can be scaled easily. There can be multiple capacities inside Fabric tenant so these can be dedicated for specific jobs and dynamically scaled to match the needed demand.
At this point in time, these capacity units can be acquired in three different ways:
- PowerBI Premium capacities can be also extended for Fabric item usage
- Fabric capacity units that can be obtained from the Azure side
- Fabric Trial which provides a free 60-day tryout period to get familiar with MS Fabric
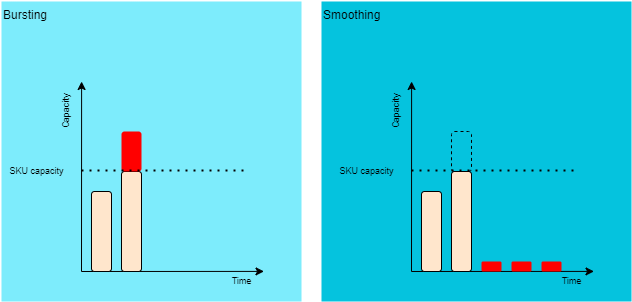
The usage of the capacity within the Fabric items has some cool features. The first one is called bursting which basically means that Fabric automatically can exceed the provisioned compute resource temporarily to execute a specific workload faster. So for example, if the capacity´s SKU is set to F64, Fabric can harness even more compute power which normally is available only in higher SKUs. This brings more flexibility in unexpected situations and gives some peace of mind for admins to know that these spikes don´t paralyze the whole environment. With bursting, Fabric clears the high demand situation with more power and borrows the capacity for it from the future as it is going to be explained in the next section.
The other one, which is tightly coupled for the bursting feature, is smoothing. To steer clear of capacity to be burned down in high-demand workload situations, Microsoft Fabric automatically smoothens the overused capacity evenly in bursting situations. So if there is a sudden need to exceed the allocated SKU´s compute with the bursting feature, Fabric smoothens the exceeded capacity for a minimum of 5 minutes or up to 24-hour time period. What it means is that the capacity that was used over the SKU boundary is dripped down for a period of time after the job is completed. This erases the need to set jobs to be started one after another to avoid performance issues but instead enables running them in parallel or in any way that the situation needs without worrying about performance issues. Playing around with these features is going to be interesting as it gives more possibility to use the full potential of the reserved capacity.
Observations Along the Way
As I mentioned in the beginning, Zure has been working with Microsoft Fabric from the get-go in different customer cases, gaining an understanding of the current status and the capabilities of the product. Here are some observations along the way:
⭐ The OneLake concept is working really well. Separating different business units into different domains and workspaces inside Microsoft Fabric brings more transparency and governance, but the shared storage and shortcuts enable combining data fluently in different use cases. On the downside, uncontrolled data sharing inside Microsoft Fabric is a fast track to failure. Strong governance and management processes are a must and equally important as the technology side of data projects.
⭐ True separation between storage and compute layers breaks down barriers in data platform solutions. The possibility to use the same data with different workloads gives a lot of flexibility in choosing how to approach business problems. Mixing Spark and the Polaris engine-based SQL workloads gives the best of both worlds. Spark engine can do the heavy lighting in larger datasets by transforming and validating the data. Warehouse items are able to use the processed data to provide a structural data presentation layer for analytics or any other parties.
⛔ Version control and deployments are still lacking capabilities to bring more automation and development tools to maintain Fabric items. This is a must-have feature that needs to get better, and Microsoft is planning to enhance these areas still during this year according to their roadmap. Bearing in mind that Fabric is still in Public Preview and missing CI/CD features and some other crucial features it is as of now quite there yet to provide a stable production-ready environment.
All in all, Microsoft Fabric is a promising new up comer in the field of data. Microsoft Fabric is Microsoft's ecosystem response to the intensifying data & AI competition. The product is still in the Public Preview state and for a reason. Microsoft is continuously developing Fabric, and from time to time, various mystery errors and bugs bubble up. This combined with the fact that work needs to be done through the portal mainly gives some frustration for developers Even though, Microsoft Fabric is looking promising, and fills a missing piece in the Microsoft data offering.
Zure is going to be following closely what happens around Fabric and will dive deeper into these interesting aspects of it in the coming blog posts so stay tuned and keep an eye on our blog.


