
Last spring me and my colleague Lauri Lehman published a blog about fine-tuning OpenAI models for custom applications. While our experiments weren't a (complete) success, we ended that blog post with a plan to follow-up on how to build a more reliable model for our scenario (matching developers and projects). With the pace that GenAI and Large Language Model (LLM) applications have progressed, we are now able to bring you the promised follow-up discussing some key advancements (for the more time-conscious developer) that Microsoft and OpenAI have delivered since our last blog.
Starting point
If you read the last blog about fine-tuning, you know that while fine-tuning showed promise in theory, it also proved rather catastrophic in practice. That is why we then turned our attention to what has became known as RAG or the Retrieval Augmented Generation pattern. With RAG having become the standard approach to chatting with one's own data, we wanted to see how far we can get with some of the new tools Microsoft has launched since Ignite. The tools have been chosen based on the promise that they simplify and expedite LLM development by wrapping a lot of the stuff we previously had to code our selves as Azure resources and services.
The goal, the motive
We wanted to find out how much the maturity of the Azure OpenAI offering has increased during the past year by finding out how some of the bog-standard Microsoft services fare with our task of matching developers and projects. As we remember, this task was beyond a fine-tuned OpenAI model last spring.
The point of having such a simple scenario was to be able to focus on the tech and its capabilities without any business complexities hiding lackluster capabilities. Furthermore, as ready-baked RAG infrastructure solutions such as Azure GPT-RAG are nowadays plentiful and ever-evolving, we see more value in evaluating the performance of the up-and-coming tools in the Azure palette.
The tools
The tools/wrappers we used in this experiment are Prompt Flow, Integrated Vectorization and AI Studio. The reasoning behind Prompt Flow is that it is a service that wraps and automates a lot of the boilerplate- and management drudgery of creating LLM solutions. For Integrated Vectorization, the same applies as it automates the process of creating vectorized indexes for RAG scenarios (something we had to implement ourselves even last summer). Azure AI Studio is a new service that gathers all AI development tools under one portal, from model development to testing and deployment.
Prompt Flow
Where we see promise and interest in Prompt Flow are the enterprise- and application lifecycle promises it makes. Until now, building enterprise-grade LLM apps in Azure has been somewhat strenuous as all the qualities that make apps enterprise-ready have needed quite a bit of custom code in their implementation. Furthermore, managing the lifecycle of LLM-based apps has so far been rather manual and testing them painfully manual if not straight undoable due to the non-deterministic nature of LLM outputs.
Prompt Flow offers a visual user interface for developing customisable LLM apps that integrate with other Azure AI Services like Cognitive Service APIs and AI Search. You can build an LLM pipeline from smaller components that perform specific tasks like LLM completion, function calling or a vector database search. Connections to other services are managed in the workspace so that their credentials are stored securely and can be passed to the task modules via parameters.
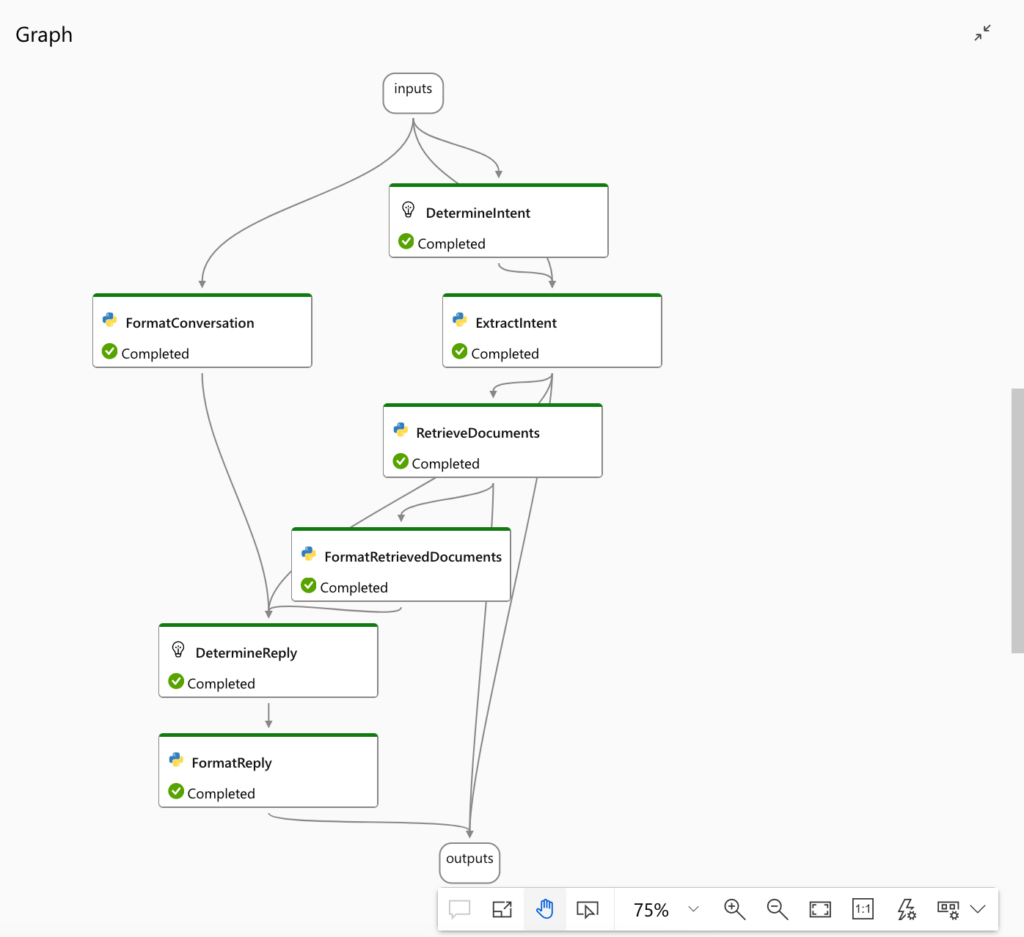
Prompt Flow also contains built-in components for standard tasks like LLM completions and definitions of prompt templates. It also allows the user to write their own tasks in Python, enabling customisation of the whole LLM pipeline as needed. For testing purposes, Prompt Flow includes various evaluation metrics for LLMs so that the user can compare different versions of a model by running a bulk evaluation against a static test dataset. Finally, the best version of the model can be deployed as a REST API endpoint by just a few clicks from the Prompt Flow UI. Thus the tool also enables LLM DevOps (LLMOps) for managing the environments and lifecycles of LLM-driven applications.
Integrated vectorization
While Integrated Vectorization is mostly a backend wrapper for a more focused task, the same core concept of automating steps that before required several components and custom code applies. With vector-based searching having become the standard for RAG search scenarios, we wanted to see how the automated tool fares with a rather tricky dataset with a lot of shared keywords between documents.
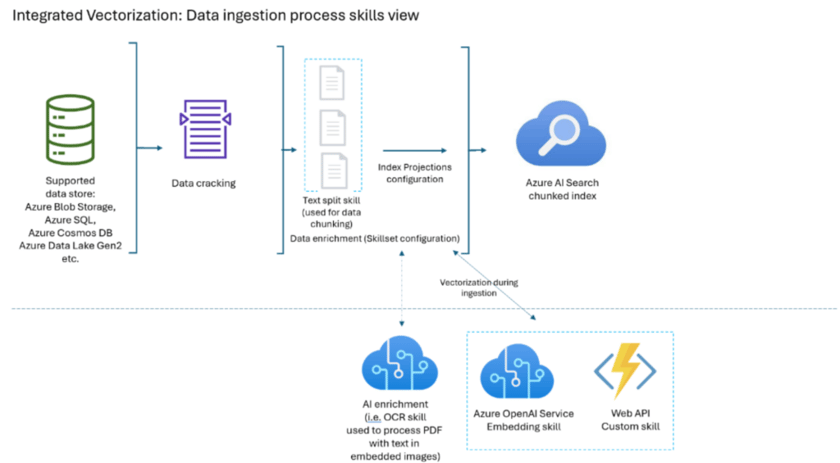
As for what the integrated vectorization tool actually does, is that it takes three previously custom-code dependant actions of
- Embedding source texts to vectors
- Chunking large source texts to smaller chunks of text
- Converting query text to vectors when searching
and automates their execution. While one still has to understand the processes of vectorization and chunking to benefit from the automation, it does allow for a streamlined application architecture and development experience. The automated components (AOAI Embedding skill and Web API custom skill) can be seen in the diagram below.
AI Studio
AI Studio is a one-stop-shop... workspace service for developing and publishing LLM models in Azure. For example, OpenAI and Cognitive Service APIs, managed Virtual Machines for development and deployed online endpoints can all be hosted and managed from within the AI Studio. Using these features has previously required dedicated instances for each service. AI Studio acts as an umbrella service for all these AI-related services, improving the efficiency of AI developers and supporting collaboration between various developer roles.
The process
The process of (nearly) automatic LLM backend building is rather simple. For Prompt Flow, follow this guide to get started. For Integrated vectorization, see these instructions to create a vector index. As can be seen from the guides, setting the services up is a very simple clicking process, especially if you have the required Azure resources already set up. The only issues for us were the random preview-related bugs where a needed resource wasn't visible in a dropdown menu or something of the like.
However, even with the preview quirks it was still only a few hours job to set everything up and check that on the surface both the prompt flows and the integrated vectorization seemed to work. Therefore, it was onwards to the actual task!
Use case
This time, instead of inventing more Bob Bobssons as we did last time, we took the CV's of our actual developers for more variety. Then, we let the automated vectorization turn them into vectorized values in our Azure Search index. In this scenario the chunking function was a bit overkill due to the one-pager nature of the CV's, but we tested it separately with long docx's and pdf's and were rather happy with it. Furthermore, as a side note, one could imagine building index projections (one-to-many indexes of indexes) for larger and more complex datasets than ours, but that is outside our scope this time.
First impressions
With the index loaded with vectorized CV's, we turned to Prompt Flow and set it up with the template provided, created the connections to the Search index as well as our Azure OpenAI model, created an endpoint and started testing and researching.
Something we noticed first was that Prompt Flow generates a LOT of system messages and instructions for the LLM model, possibly producing considerable overhead depending on the usage scenario. These instructions are only available after the model has been converted to a Prompt Flow. The Playground version of the model has a much simpler system message template, but it is unclear if the additional instructions are also used in the Playground backend. In any case, it is recommended to review the generated Prompt Flow template and modify it to the use case in question, as it can generate a lot of unwanted clutter. Searching for documents usually generates a lot of overhead as well, since the search by default returns more than one document for each query. Limiting the size of the final prompt is therefore crucial to avoid exceeding the maximum token limit and improving the speed and cost-efficiency of the application.

Using Prompt Flow is rather self-explanatory but it might require some coding experience to get started with. Once you familiarize yourself with the task input and output system, it becomes clear how information is passed between tasks and how the execution order of the flow is determined.
For an experienced coder, the integration features are one of the most attractive aspects of Prompt Flow. Connections to external services like Azure OpenAI, AI Search and Storage Account can be defined in the project settings. The authentication secrets are stored in the system and can be imported to Python scripts securely via input parameters. This removes a couple of extra steps for developers and reduces the anxiety of system administrators.
Experimenting with Bulk Evaluation
One of the most useful features in Prompt Flow is bulk evaluation. With this feature, you can test LLM applications in the same way as the model selection process in traditional machine learning. In this process, a set of metrics are chosen to represent the model quality and a test dataset is constructed to represent the "correct" or canonical answers (also known as "ground truth"). In the case of text generation, there is usually no single correct answer so we shouldn't expect a 100% match for the best model. The best model merely produces outputs that are closest to the correct answers. Thus, the evaluation metrics and the test dataset provide the basis against which different models can be compared.
Testing new versions of an LLM application with bulk evaluation is straightforward. Each run is preserved in the system so new versions can be easily compared against historical versions. This allows to experiment with different prompts and other LLM logic while keeping a historical log of each run without additional effort. Another use case for bulk evaluation is the optimization of the base LLM model used. When creating LLM applications, developers often start with the most high-end model available and then gradually decrease the quality of the model until it no longer meets the requirements for the task. The bulk evaluation metrics can be directly used for this kind of optimization, since we can track how the quality decreases as the model changes and observe when it drops below a certain threshold.
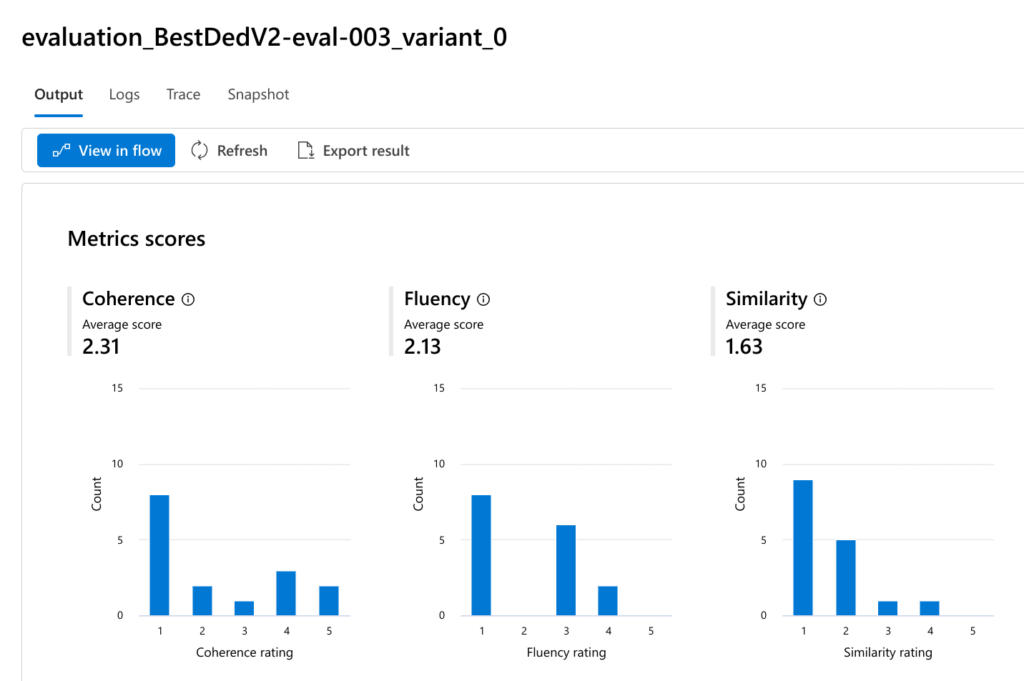
The screenshot above shows an example of bulk evaluation results for a single run. In addition to the total metric value, the graphs also show the distribution of values which might give more insight into the quality of responses. Not all of the metrics are related to the closeness between the ground truth value and the value produced by the LLM. For example, the coherence metric measures the internal consistency between the sentences in the LLM answer and the fluency metric indicates how grammatically and linguistically correct the answer is. See the official documentation for more information about each metric produced.
The verdict
We set out to figure out how far we could get with the bog-standard GUI tools that Microsoft has developed for RAG scenarios, with the intention of seeing how well they would fare with our BstDed developer/project matching scenario. Based on our testing, both the concept that drives Prompt Flow (one stop shop for LLM development and deployment) as well as the near-automatic RAG search deployment showed great promise, even if both solutions are in preview phase.
However, there are still bumps on the road to creating a perfect developer matcher. For example the habit of over-guardrailing everything is very present in the system prompts Prompt Flow creates. The vectorization wrapper created by Microsoft sometimes crashes internally with no way to debug. Passing too many or big documents to the LLM still hurts performance.
Even so, we believe that the benefits of using Prompt Flow and Integrated vectorization to develop LLM applications far outweigh the downsides:
- Working RAG pattern template and vectorized search index
- Customization of LLM logic (Python scripts, Langchain..)
- Managing integrations at the project level, with secure secret management at code level
- Evaluating and comparing different prompts and logic with historical logs before publishing a model
- Deploying and host the model as a REST API endpoint with a few clicks
Therefore our recommendation is to get out there and give them a shot!

