
Machine Learning (ML) models are often criticised for being hard to interpret. Many ML models are called "black-box" models, because there is no clear relationship between a model input ("feature") and the model output (prediction, score, etc.). From a technical viewpoint, this obscurity arises from the complexity and non-linearity of the model. This is particularly true for neural network models that may consist of billions of parameters, LLM models such as GPT-4 being the best examples.
Interpretation of complex ML models is not impossible, however! Techniques have already been developed to understand the behaviour of ML models and model interpretability is being actively researched in academia. In this post, I introduce some tools and techniques for model interpretation which are provided by the Azure ML Responsible AI (RAI) Dashboard.
The RAI Dashboard is a feature of the Azure Machine Learning Service that assists Data Scientists and ML Engineers in understanding the model bias, interpreting the results given by the model (both globally and locally) and diagnosing the model errors. The features in the RAI Dashboard are designed for reducing the model bias based on people's personal traits, but it is also useful for understanding the model behaviour more generally and improving the overall accuracy of the model.
In this blog I will introduce the RAI Dashboard and show you how to get started with it. I also highlight some of the features in RAI Dashboard, such as error analysis and feature importance. You will also learn about cohort analysis and how it helps to understand and mitigate bias in ML models.
Responsible AI Dashboard
Microsoft released the RAI Dashboard back in December 2021 and has since added multiple features to it, including debugging of image recognition models. The RAI Dashboard UI is part of Azure ML Studio, the graphical user interface to the Azure ML Service.
To start using the RAI Dashboard, you must first train a machine learning model and publish it to the Azure ML Service as a registered model. There are some additional requirements that the model has to satisfy so that a RAI Dashboard can be created for the model. The most important requirements are:
- The model is trained in Python using the MLflow framework
- The model is a regression or classification model from the Scikit-learn library
- The input data used in analysis must be a Pandas DataFrame saved in Parquet format or a registered Dataset in Azure ML Service of type MLTable
Note that these requirements might change as the Azure ML Service evolves. See the official documentation for the full list of current requirements.
Creating a Responsible AI Dashboard
The RAI Dashboard can be created using the Azure ML Studio UI, the Azure CLI command-line tool or the Azure ML Python SDK (v2). To create an RAI Dashboard, you must first train a machine learning model using the MLflow framework and the sklearn Python package and register the model in the Azure ML Service. If you don't have an ML model in this format, see this Azure ML tutorial to train a model for testing purposes.
The RAI Dashboard is created by an Azure ML Pipeline Job that runs on an Azure ML Compute Cluster. Before creating an RAI Dashboard, you must therefore create a Compute Cluster to run jobs on. Follow the instructions in Azure ML documentation to create a Compute Cluster, if you don't have one yet. I recommend to choose at least STANDARD_DS3_V2 size for the Cluster, otherwise you might experience timeouts in Pipeline Job runs. Also make sure that the minimum number of nodes is set to 0 so that the compute capacity is scaled down after the Pipeline Job has finished.
Once the above requirements are met, the Dashboard can be created in Azure ML Studio UI by opening the previously registered ML model from the Models tab on the left. Then click on the Responsible AI tab in the model view and press the Create Responsible AI Insights button to start the Dashboard creation wizard.
Follow the steps in the wizard to create the RAI Dashboard. You can use the same training and testing datasets that were used for training the model (given that they are in a format suitable for RAI Dashboard). You must also choose the model type that determines which components are available for the Dashboard. The following model types are supported at the time of writing:
- Regression
- Binary classification
- Multiclass classification
The content of the RAI Dashboard can be customized by changing the settings in the Dashboard creation wizard. Don't worry if you don't recognize all the concepts mentioned in the wizard, just add them using the default settings provided by the wizard. You can familiarize yourself with the new concepts by experimenting with different components after the Dashboard has been created.
The RAI Dashboard is always connected to a specific model registered in Azure ML Service. The data used in the analysis must also be defined at the creation time of the Dashboard. If you wish to analyse the model with a different dataset or analyse a new version of the model, a new version of the Dashboard must be created.
Responsible AI Dashboard Components

The RAI Dashboard consists of various components, such as:
- Error analysis
- Feature importance (global & local explanations)
- Counterfactuals
- Causal analysis
If the Dashboard is created from the Azure ML Studio UI, these components are included under the broader modules like Model debugging or Real-life interventions. If more granular control of the components is required, use the CLI or Python method to create the Dashboard and add the components one by one.
Note that using the RAI Dashboard for analysis requires an Azure ML Compute Instance, a managed virtual machine hosted in the Azure ML Service. Follow these instructions to create your personal Compute Instance and start using the RAI Dashboard. If you want to be cost efficient, the size STANDARD_DS1_V2 might be sufficient to run the analyses, but I recommend at least STANDARD_DS2_V2 for a smooth experience.
Error Analysis Component and Choosing a Cohort
In the following, I will use a case example from Ruth Yakubu's RAI Dashboard sample repository that uses the UCI's Diabetes 130-US hospitals for years 1999–2008 dataset as source data. The ML model is trained to predict whether a diabetic patient will be readmitted back in a hospital in less than 30 days after being discharged. This is a binary classification model that uses all the available features in the dataset for training. See this 3-part blog series from Ruth for a complete walkthrough of training the model and creating the RAI Dashboard.
The Error analysis component detects subsets of data points that have a particularly high error rate (see the screenshot below). In this example, the error rate for data points with prior_inpatient > 0 is 74/278 (26.62%) while the error rate for prior_inpatient = 0 is only 94/716 (13.13%), implying a 2-fold difference in error rate between two subsets of data. Furthermore, if we look at a subset with additional constraints: 11.50 < num_medications <= 21.50, the error rate increases up to 49/143 (34.27%). Thus, the Error analysis component of the RAI Dashboard helps to identify problems in the predictions of the model and concentrating on these issues might help to improve the model further.
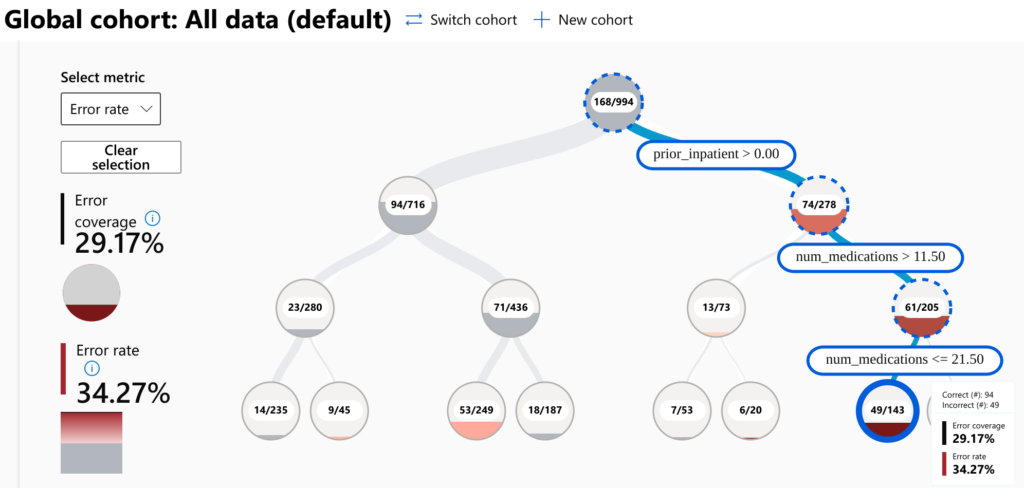
A subset of data that is defined by some constraint on the features of the dataset is called a cohort. Cohorts are usually employed in statistical analysis to track certain user groups or target groups to understand their behaviour. Tracking the subgroups might reveal patterns that would otherwise be hidden under the behaviour of the general populus. The Error analysis component helps to identify cohorts that have a particularly high error rate. The error analysis component does not include time tracking of different cohorts, but you could always create your own analysis solution to track these cohorts, once they have been identified using the Error analysis component.
Mitigating ML Model Bias
Generally, the difference in error rates is not necessarily caused by a bad model or bad data. In some cases, they might arise from the actual nature of the problem. Owing to the complexity of the illness, predicting the readmission status of patients might be genuinely more difficult if the patient has been hospitalised earlier and they have a certain number of medications prescribed. In any case, the most straightforward way of increasing model accuracy is usually adding more samples with similar values as those in the highest error cohort. Once a solid dataset has been gathered, it is also recommended to experiment with more complex models that might be able to better capture the details of the problem at hand.
The features that were discussed above are more related to the illness than the individual. If these features described personal traits of an individual, such as age or gender, and the error analysis shows that the model makes worse predictions for certain groups of individuals, it means that the model is biased towards this group and treats people unequally. This accuracy bias might be an artefact of the model or a consequence of a real-world phenomenon, such as unequal pay between genders or discrimination of elderly job applicants. It is the job of a data scientist to determine if the model can be improved to treat all people as equally as possible. Now, should the source data be manipulated so that the model gives the most equal outcome, in contrast to using real-world data with all its inherent biases? This is a hotly debated issue in the ethics of AI and I will withdraw from writing an opinion piece here!
The Error analysis component is just the starting point for analysing problems in the model. The RAI Dashboard contains many additional components and some of them are highlighted below, but a comprehensive review of all the features in the RAI Dashboard is outside the scope of this article.
Understanding Bias with Cohort Analysis

By exploring the components in the RAI Dashboard, we can dive deeper into the aspects of the ML model and discover possible sources of error. If we wish to understand better why the model performs poorly for a certain cohort, the cohort can be chosen as the "Global cohort" so that the analysis components use only data from this cohort for visualisations. The easiest way to create a cohort is to click on a node in the Error analysis component and click the Save as a new cohort button. The filters are set automatically to the values corresponding to the node. You can also create a cohort with arbitrary filters by pressing the New cohort button and defining the constraints manually.
You can create multiple cohorts and switch the active Global cohort to see different visualisations on the Dashboard. Some visualisations can also compare different cohorts, such as the Feature importances component shown below.
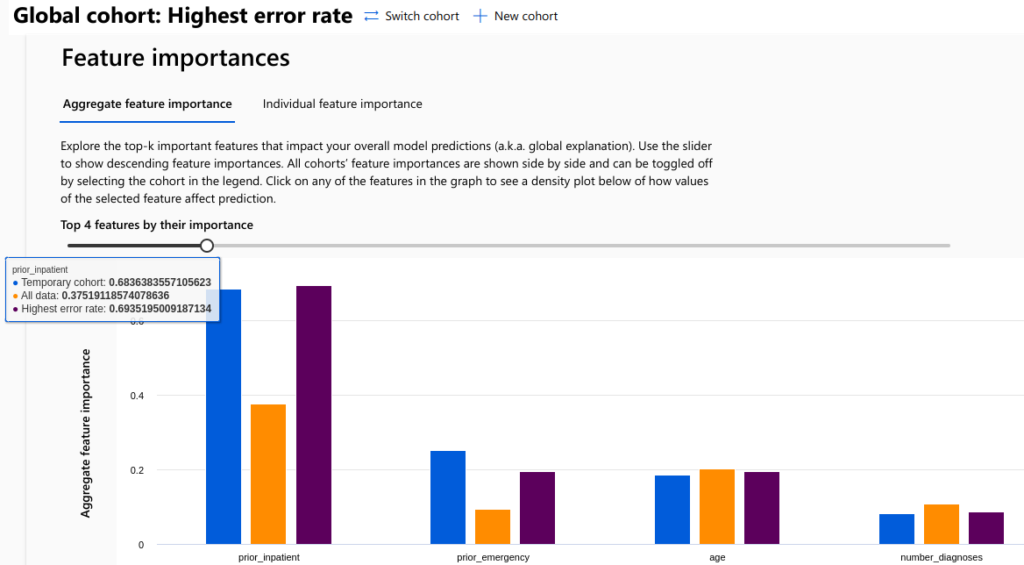
Feature importance analysis tries to determine which features of the model are the most significant in predicting the outcome. A high feature importance value means that changing the feature value also changes the predicted value by a significant amount, or vice versa. Understanding which features are the most important for the model improves the interpretability of the model and advises which features we should concentrate on to improve the model. In the picture above, the prior_inpatient feature is found to be the most significant feature in all cohorts. The second most significant feature, however, depends on the cohort.
Feature importance analysis can also identify features that are insignificant to the model. Whether these features should be included in the model, does not have a clear-cut answer and may depend on the case. In straightforward cases, adding more data for the model can increase the predictive power of the model. This might be the case if the features are independent and adding new features just gives more food for the model to consume, so to speak. Sometimes adding new features might complicate the model unnecessarily and actually decrease the quality of predictions. Again, the best advice is to experiment with different options to find the optimal solution.
Additional features
Since the launch of the Responsible AI Dashboard, Microsoft has released some new features to the Dashboard. In addition to the standard regression and classification tasks, it is now also possible to analyse free text models with the Responsible AI text dashboard and image detection models with the Responsible AI image dashboard. Such features usually require writing a custom solution. With the RAI Dashboard, these tasks can be performed without writing any code or with only a small coding effort, allowing data scientists to focus on their core tasks.
Another useful feature is the Responsible AI Scorecard. Data scientists often present their findings to team members or management using visualisations. Crafting these presentations can be a tedious and time-consuming task. The RAI Scorecard feature provides tools for creating a neat presentation based on similar components as in the RAI Dashboard. These insights can be exported to a PDF file to be shared with team members and stakeholders. This is another feature that takes data scientists time off from non-essential tasks and helps them to concentrate on core analysis. See this blog post for comprehensive instructions how to create the RAI Scorecard.
Note that the features mentioned in this section are still in the preview stage when this article is written and are therefore not recommended for production use.
Summary
In this article, I have highlighted some of the features and capabilities provided by the Responsible AI Dashboard. There are several advantages why it is worth spending some time learning to use the RAI Dashboard:
- Useful not only for reducing model bias, but also for debugging general errors and improving overall accuracy
- Very little coding (or none at all) is required to create the RAI Dashboard
- Fully customisable, choose only the components that are relevant for the use case
- Supports various use cases like classification, free text analysis and image detection
- Results can be shared easily in PDF format with the RAI Scorecard
- Spend more time doing the analysis instead of creating analysis scripts and making presentations

