
Introduction
Everyone who has created an API is familiar with the traditional approach for creating an API backend: Setting up and loading data to a SQL Database and querying data from it. To mix things up, we took a different approach to quickly and cost-efficiently building internal APIs for a larger integration platform with an abundance of data.
For this task we used Microsoft’s Azure Synapse Serverless SQL Pools on top of an existing platform-wide Data Lake Gen2 and Azure Functions with EF Core as the API layer. Furthermore, Azure Data Factory was used for file type conversions that we will discuss later. The goal was to deliver a light, yet performant production-grade virtualized API backend to serve data across the organization. In this post I will cover what we learned with my dear colleague Janne Pasanen and solved on the way.
Architecture
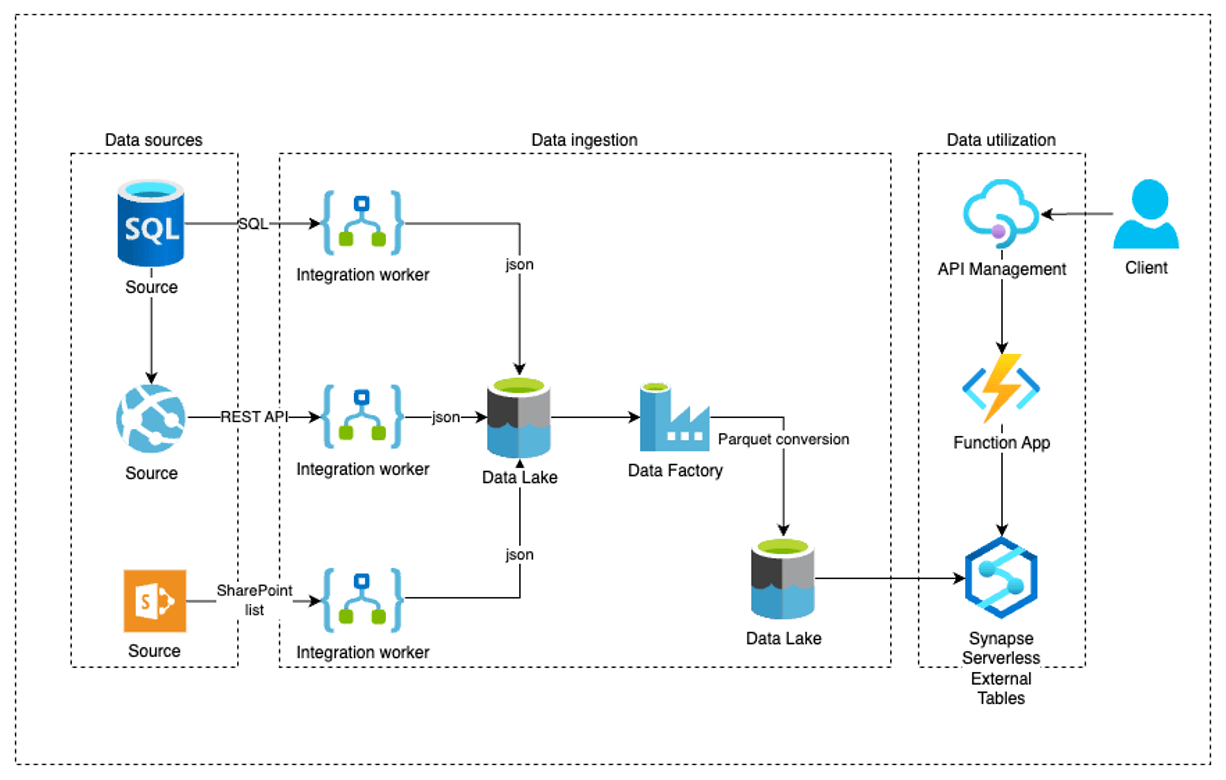
To start our journey, let us discuss the architecture we decided on. In the diagram below we can see the data sources that in the platform we were working with could be pretty much anything. In this environment Logic Apps handled most of the data retrieval to the Data Lake, resulting in a sea of JSON files. While it is possible to virtualize JSON files to Synapse entities, we quickly discovered that the performance was completely insufficient.
To solve this, we decided that it is best to use the file type Synapse Serverless runs best with: Parquet! This brings us to the next part in the diagram, that is setting up ADF pipelines that converted the relevant JSON files to Parquet (Think transferring raw/bronze files to a silver layer in a Data Lake setting). This conversion enabled us to benefit from the native support Synapse offers for Parquet files, leading to a massively improved performance.
This brings us to the whole point of this blog post, the virtualization! Indeed, after the parquet conversion we were able to directly create external tables (and views for business logic) over the Parquet files that the Azure Functions could then, with the help of EF Core, serve as APIs for consumption. To get to this point however, there were some hurdles to be overcome that we will discuss next.
Synapse Serverless CI/CD
Before being able to proceed to production with our solution, we had to verify that we could actually deploy it via Azure DevOps Pipelines. The problem was not in publishing the Azure Synapse workspace itself which, while rather complex, has been documented in blogs and by MS several times over. However, the problem was in deploying the Synapse Serverless databases themselves from one environment to another. This is, as it turned out, because Synapse Serverless SQL Pools did not (and still mostly don’t) support neither DACPAC or migration-based deployments. (As of March 2023, SqlPackage based extract-publish deployments from environment to another are now possible.)
However, this forced us to solve the CI/CD by ourselves, so we did just that. Our (somewhat simplistic) solution was to take advantage of the serverless and virtualized nature of the Synapse Serverless Pools that allowed us to create idempotent scripts that could be deployed to Synapse via PowerShell. The reason this works is that because there is no physical data or constraints related to the virtualized databases in Synapse and the data resides in the Data Lake, the database objects can be dropped and recreated at will.
To drill down to the actual technical solution, the structure is as follows:
- A control file (for example JSON) that lists the databases to be created and their use
- A main PowerShell script that does the pre-setup for each database listed in the control file, creating necessary objects and access
- SQL scripts that create the actual virtualized database objects such as data sources with Data Lake file references, tables and views
Actual script examples can be found in this repo.
Performance
When looking at the performance of a Synapse virtualized API backend, there are some limitations to take into account.
- One pool can support a maximum of 20 databases
- The maximum amount of database objects is 2^31-1!
- Synapse Serverless can return a maximum of 400GB of concurrent results sets
- There is a cap of 1000 active and concurrent query executions
Other performance findings include things such as
- Date partitioned data performs slow when combined with wildcards, for example an external table referring to import/accounts/2022/* would result to poor performance
- There are no indices or keys to manage, only partitions in the source files themselves
- Statistics help performance a lot, luckily they are auto-generated for Parquet files
- Minimizing column sizes is especially important
- With Parquet, fewer and bigger files are preferable to a lot of small ones
- Running functions in Consumption Plan increases latency due to cold start (can be easily mitigated by switching to App Service Plan)
Implementing a Function API
Using a Function with a Synapse Serverless DB is rather straightforward and in many ways similar to using a standard Azure SQL DB, with a few differences. The first difference is related to using EF Core with Synapse: due to the lack of key constraints and indices, these need to be manually mapped in the function to be able to utilize EF Core functionalities such as navigation properties. The lack of database keys makes query splitting a good option when executing queries with lots of joins.
Furthermore, as described later in this post, access management from the Function to the Data Lake data needs a bit of attention.
One key difference to a regular SQL DB is the limited support of data types. Workarounds for unsupported data types can be found here.
Access management and security
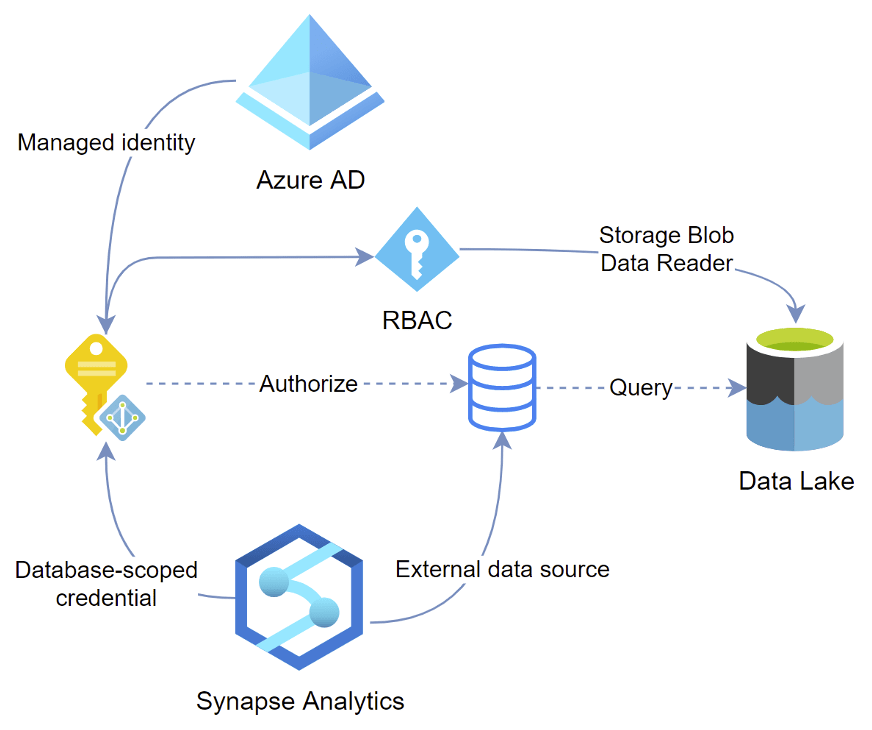
Due to the several layers of access and related Azure resources, the access flow from for example an Azure Function to retrieving the data from Data Lake via Synapse is a bit complex, therefore it is described in the following diagram. Here we see that the Synapse managed identity uses a database scoped credential (created with the main PowerShell script) to access the external data source. Here another check is performed regarding whether the Managed Identity has suitable (Storage Blob Data Reader/Contributor) role-based access to the Data Lake itself.
Conclusions
All in all, the goal of a light yet performant, production-grade virtualized API backend has been met with the aforementioned solution. Even the lackluster out-of-the-box CI/CD support is circumventable with some good ol’ scripting, and performance has been solid for the lightweight use cases the solution was designed for. To further improve the development experience, better tooling, documentation and CI/CD flow would however be very welcome. Nonetheless, for a lightweight API backend on top of an existing data lake, do give this approach a shot!