
Artificial Intelligence (AI) has lately gained a huge amount of attention in companies big and small. The rapid advancement of AI and machine learning technologies has made pre-trained models like OpenAI's GPT-4 more accessible than ever. Adding to this, Microsoft's Azure cloud platform offers a powerful and flexible environment for customizing these models to provide value in organization-specific scenarios. The goal of this blog post is to demonstrate the customization of such models using the Azure OpenAI service with an example use case. This blog post has been written together with our resident Data Scientist Lauri Lehman.
To some extent, pre-trained OpenAI models can be customized by providing some domain-specific information as part of the input prompt. This technique is called few-shot learning. The input data is however restricted by the prompt length (of the order of a few thousand words) and incurs extra costs and latency. If the amount of domain-specific knowledge exceeds this limit, the model needs to be re-trained to take all data into account. This re-training process is called fine-tuning. For a more comprehensive introduction on fine-tuning, check out the official OpenAI documentation.
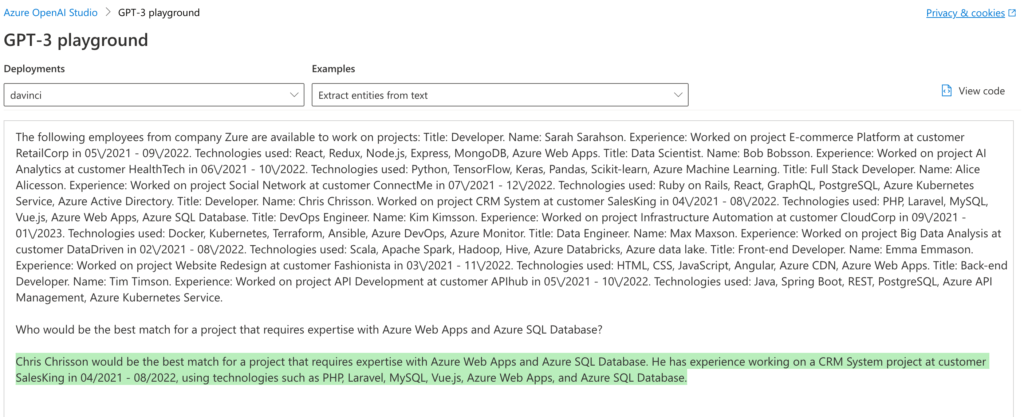
The use case
To demonstrate fine-tuning, we decided on a matching use case, in this case between developers and projects. To find suitable developers for given projects, we built a recommendation solution (similar to what we built earlier with custom algorithms and machine learning). The solution consists of a simple website that in the background utilizes an OpenAI model that has been fine-tuned with a custom dataset to recommend developers from a given pool for a project based on their tech stack. To give some flavor to the project, we (creatively) named it Project BestDev and thought it would be thematically coherent to allow DALL-E design the logo for it, which it did... sort of.
The solution
The project consists of four parts, each discussed further in the blog post:
- The training data to fine-tune the model
- The model to be trained
- The API used for relaying prompts and answers
- The website/UI front end for the user
Fine tuning
The training data
Quantity
Fine-tuning a model for a given scenario is a very iterative process (and prone to several pitfalls, as discovered on the way). The most important ingredient is obviously a high-quality dataset that contains essential information about the target domain and use case. The dataset should contain prompt-completion pairs, with prompts representing possible user inputs and completions representing desired outputs or answers from the model. Both prompts and inputs should be free-form text in a conversation-like format. In our use case, the original data (developers and their tech-stack) has a rigid code-like structure, so we needed to pad it with descriptive words and structures to make it more reminiscent of a question. It is also important that the prompts and completions are similar to the expected inputs and outputs of the model.
Our first smoke-test contained around 10 handcrafted examples describing developers and their experience of different tech stacks. While this showed that the model can produce content that is somehow similar to the desired output, the model was not able to deduce our business logic, meaning that it was not able to pick reasonable employees for projects based on their project experience. The model often produced nonsensical output, repeating some sentence structures or confusing between people's names and names of technologies. Therefore if you only have a handful of examples from your domain, few-shot learning is the recommended approach and also worked better for our use case.
To experiment further, we used GPT-4 to generate a hundred rather repetitive prompt-completion examples with randomized project tech stacks and names. This resulted in a noticeable improvement in model performance. The model did not generate as much weird outputs as long as the input prompts are similar to the training examples. According to OpenAI, the accuracy of the model grows linearly as a function of the number of training examples, so it is expected that the model can still be improved significantly by adding even more and varied training data. For this type of problem, OpenAI recommends several hundred examples, but we were delighted to see that the model begins to understand the use case even with a rather small dataset.
Quality
In addition to quantity, data quality is also crucial for fine-tuning. There are several best practices on how to present your fine-tuning dataset, for example how to separate the example prompts and the example answers the model should give out. The OpenAI API also includes a data preparation tool that can be utilized to improve the fine-tuning dataset. The tool helps with checking that your fine-tuning dataset conforms to the recommendations and best practices when fine-tuning, and helps to convert other data formats to the JSONL type that is used.
Designing the training dataset proved to be a bit challenging, as there is scant information available publicly on how to construct the input prompts and completions in an optimal way. It took a while to figure out the best way of providing additional information to the model. We wanted the model to understand that there is a pool of employees available for projects and the model should suggest employees from this pool only. This information is different from the default use of the model, which is asking for a suitable candidate employee for a given project without any references to the existing pool.
To provide contextual information for the model, we ended up creating a single example that provides the information as an input prompt. This is just a list of available employees along with their relevant work experience. The completion does not matter in this case so we just replaced it with a dummy confirmation message. The rest of the examples are similar to the intended inputs and outputs of the model. This method seemed to work reasonably well even with a small dataset. The model was able to only pick the employees from our employee pool, even though it still at times hallucinated their experience.
A few examples of the training dataset with GPT-4 generated facts:
{"prompt":"Who is the most fitting candidate from Zure for project Image Recognition System at customer ImageRecogPro with technologies like Python, TensorFlow, and Pandas?\n\n###\n\n","completion":" Bob Bobsson, because they have experience with Python, TensorFlow, and Pandas, which are relevant to the Image Recognition System project.<END_OUTPUT>"
{"prompt":"Which Zure candidate is best suited for a project called Smart Home Automation at customer HomeTech, using technologies like Docker, Kubernetes, and Azure IoT Hub?\n\n###\n\n","completion":" Kim Kimsson, because they have experience with Docker, Kubernetes, and related Azure technologies, which are essential for the Smart Home Automation project at HomeTech.<END_OUTPUT
The model
The model we chose for this project was curie, but there are several different models for different scenarios with different capabilities. For this task, we wanted to try out curie due to it's capabilities with classification and question answering.
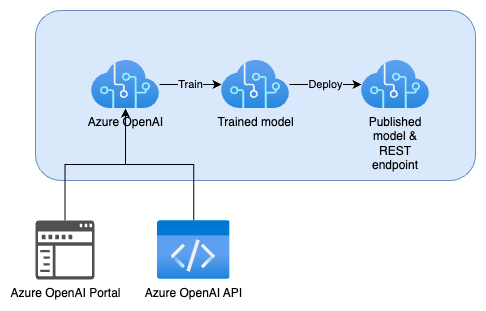
The diagram above demonstrates the generic flow of fine-tuning a model in the Azure OpenAI Service. The Azure OpenAI Studio (in the Azure Portal) is a user interface to the Azure OpenAI Service and can be used for training and deploying OpenAI models without writing any code (although the same can be done with code as well). Upload a training dataset to the Azure OpenAI Service using the Azure OpenAI Studio to start training a model in a few clicks. The trained model can be deployed to the Azure OpenAI Service as a REST endpoint, ready to be consumed by other applications like chatbots and other user interfaces. If you require more control over the training process, OpenAI provides SDK's for training and deploying models programmatically.
When we started the project, we experienced some failures with deployments to the Azure OpenAI Service. They were fixed in a couple of days and the service has been running reliably since. The service has become very popular and this has resulted in long waiting times for fine-tuning jobs. While the training process itself only takes a few minutes, the queuing time is usually about half an hour and the REST endpoint deployments may exceed 90 minutes. Developing models iteratively can therefore be a slow process, but we expect the service capacity to grow in the future.
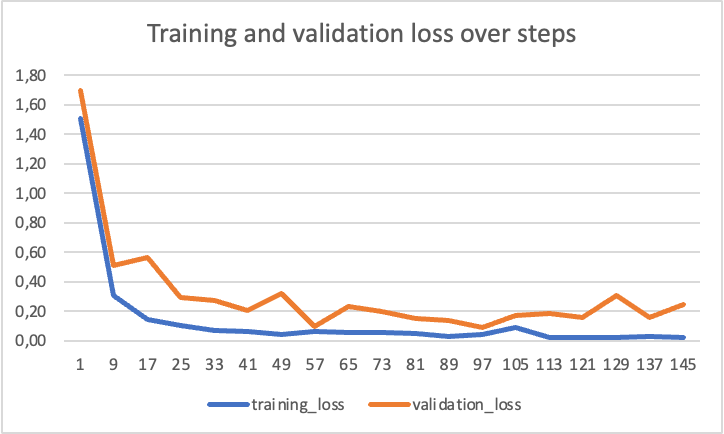
After training the Azure OpenAI service also generates a csv file that can be used to evaluate and analyze the results of the training with a given dataset. The file contains several interesting statistics for those more versed in the world of machine learning and model training, for example the training and validation losses when the model learns the new dataset. Some of the training results as well as the hyperparameters used in the training are also available in the Azure OpenAI Studio.
The app
To showcase the fine-tuned model developed with Project BestDev/BstDed to a broader audience, we also developed a trivial front-end application and a small API backend for interacting with the model. The front-end simply asks the user to describe their project and sends the description to the Azure Function backend, which then sends the question as well as the model parameters to the fine-tuned model that has been deployed to Azure OpenAI. The answer (ie the developer recommendation) is then relayed back to the user.
Results
The results of the both positively and negatively surprising. As of the main goal of the fine-tuning, that is to enable the fine-tuned curie model to answer to questions based on a custom dataset, the app performed satisfactorily and responded well to adding broader training datasets. When asked about a given project tech stack, it was able to combine the requirements with a suitable developer, at times even making "close enough" suggestions of close matches.
However, the curie model also seems very prone to "catastrophic forgetting", that is over-emphasizing the fine-tuned material at the cost of previously learned information. This was demonstrated by the almost total loss of random conversational capability not related to developer matching. An additional by-product of the fine-tuning was the tendency to leak unrelated information if the model did not find a close enough match from it's now much more specialized knowledge base.


Conclusions
In conclusion, fine-tuning OpenAI models for custom scenarios shows promise but also limitations. As our experimentation has demonstrated, it also requires understanding of both the problem to be solved as well as the models and ther limitations. Nonetheless, by carefully curating a quality dataset and continuously iterating the dataset as well as the model, we believe it is possible to create useful new (and enrich existing) applications.
Furthermore, to tackle the overspecialization issue, we might follow-up this demo with an updated model that approaches this recommendation task by using embedding to improve the model's text understanding and understanding of similarities. Stay tuned!

