
In earlier parts of this series we covered the sandbox landing zones, landing zones accelerators and more complex landing zone software projects. In this last part we will take a look at some potentially more complex cases and workload accelerators which appear to be a simple way of deploying infra but might skip some of the complexities they should not skip.
Application accelerators and Landing Zones
The last difficulty level are specialized landing zones like Data landing zones, and different application landing zone accelerator examples. Both of these are based more on speculation than actual knowledge, since I have not extensively worked with either, so take this with a large spoonful of salt.
Let's tackle the accelerators first. I can identify three kinds of accelerators; landing zones accelerators that we already covered in part 2, accelerators that provision some kind of centralized service like API Management and accelerators that provision resources for a workload landing zone.
The first challenge with accelerators is that they are, first and foremost, examples. The APIM accelerator includes implementation for backend functions, which as an example, is great, but is that the suggested way of hosting API Management? There probably are use cases for deploying API Management per workload (and per environment), but APIM is the kind of prime candidate for a centralized service, where an organization would benefit from a shared way of publishing and managing APIs.
Accelerators, like the API management, make most sense if they are to be used as centrally managed service, since they tend to deploy a single, if complex, service. They also align well with the landing zone architecture - a centrally managed service tends to need a subscription, has connectivity considerations, and probably some form of financial considerations. There are additional complexities in making this kind of service available for workloads, but those are solvable if things are well planned.

The more complex use cases are the accelerators that are clearly used to deploy a re-usable infrastructure package to a landing zone. Consider the App Service Accelerator. It's a nice example, with pretty comprehensive deployment parametrization and the IaC implementation includes support for some supporting resources like Azure SQL, Redis and App Service Configuration.
However, it comes with the complexity of both configuring networking and having to do some decisions on spoke virtual network configuration. Arguably, if you go with subscription vending model that is the current suggested way in Cloud Adaption Framework, someone needs to make those decisions for the workload in any case.
One of the challenges with accelerators is that your workloads end up with implementations that appear to configure landing zone networking, but in reality they need a lot of help later in setting for example peering, routing and required security configurations. So as the platform engineering dude you'll end up doing a lot of debugging and configuration for them, probably after a lot of escalation and tight schedules - basically solving the same problems you would need to solve with a centralized solution, but individually for every team. You can mitigate this by having clear requirements and/or policies that the workloads need to adhere to, and at least spend some time thinking about before requiring additional help.
I would also argue that with enterprise customers, there tends be a lot more variety with the infrastructure elements used per workload, and if workload teams start to use these kind of accelerators and customize them to their own needs, you end up with a lot of Infrastructure as code implementations that seem to follow similar architecture, but in reality, don't.
Just applying an accelerator as your solution for the application landing zone is a pathway to managing spot solutions for workloads - fine if the solutions are similar enough (for example, every application landing zone is just one or several virtual machines which host web apps with similar connectivity requirements) or if the scale is small enough that your team can handle landing zones as pets rather than cattle. Within a larger enterprise, you end up with a platform team that manages multiple custom workload infra solutions for the application teams.
Having said all that, there is a scenario where deploying a spoke network and assorted things like network peering make more sense, and that is the platform engineering self-service one. Does it make sense to take an application landing zone accelerator as the base of development for self-service deployment catering to multiple workload teams? Probably not. But it can certainly act as a starting point for doing those prototypes.
Data landing zones
Really difficult cases, like the data mesh -type things, you probably want to implement as their own thing. A single or even several data landing zones could probably still fit within the same structure as your application landing zones, especially if the team(s) handling your platform have knowledge of data management operations. But with more complex scenarios the concept of a landing zone starts to drift quite far from application landing zones, especially when the documentation talks about nodes in a Data Mesh.
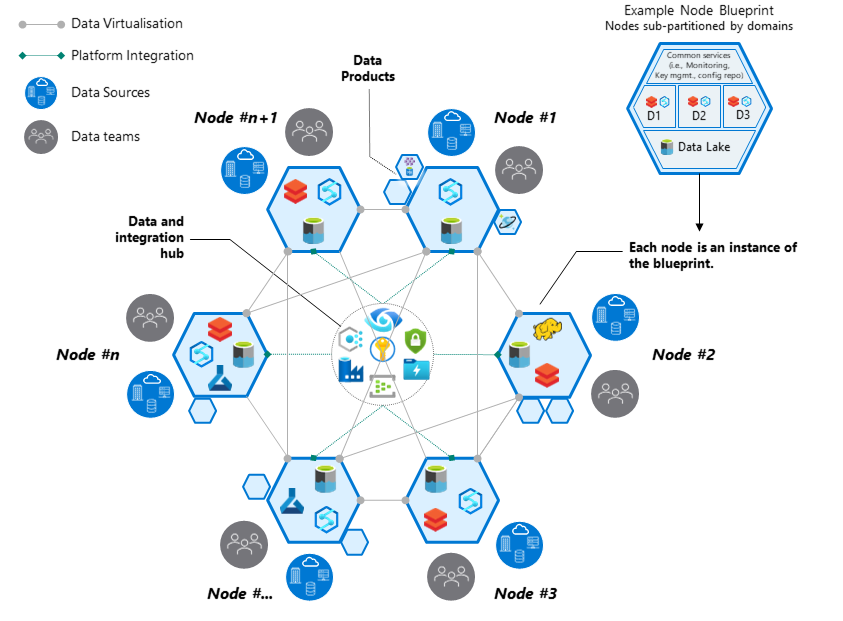
Data Mesh architecture shamelessly copied from Microsoft Learn.
In all of the scenarios you are dealing with centralized services and resources, some amount of data landing zones, and data application infrastructures, which in some cases are bundled as Data Products. The network topology seems to be a mesh - landing zones peered to each other and centralized services - rather than traditional hub-approach. On top of those, the enterprise probably has a hub as well - the platform landing zones. You will end up with a really complex architecture, no matter from which angle you look at it.
Since the documentation mentions magic words like network isolation, the nodes pictured above probably share some common features with bare-bones landing zones. It also mentions the self-service as the way to provision data management landing zones and to hide away the technical complexities of everything we have discussed about previously. So basically we are talking about the same thing as with platform engineering scenarios; a single deployment, or a series of deployments, that deploy and configure both the landing zone and the data domain resources.
While this can appear a straightforward proposition, bear in mind that no two data domains are probably identical, so what you'll likely end up designing is the best of the both worlds (and I use that term very lightly); a landing zone implementation that encapsulates network configuration and the variability management of data domains and/or data products. Designing the network configuration to be as simple as possible probably pays of here.
I have a hunch that the variability management of your Infrastructure as Code is going to be somewhat big topic in near future, and not just with most complex scenarios like data meshes. You are bound to end up somewhere in that problem space every time someone wants a one-size-fits-all -solution, be that a landing zone, a shared Bicep (or whatever your tool of choice is) module, a golden template or a self-service deployment.
And there it is - the last part of the series, where we attempted to divide landing zone deployments into four levels of difficulty. As is usually the case, such exercise is a bit futile as real life cases seldomly neatly fit into one single level.

