

I am currently assigned to a team finishing up a project that has been running for one and a half years. The project was very successful and had many things which to learn from, so I thought writing about the project and the technical lessons learned from it would be a good idea. There were good "soft skills" lessons, but this post will focus on the more technical aspects of the project.
This post is going to be sort of "technical tips and tricks" to give you useful ideas for other projects. I'm going to avoid revealing the customer and the project in question, so let's use the name "APL" for this application.
Short technical introduction
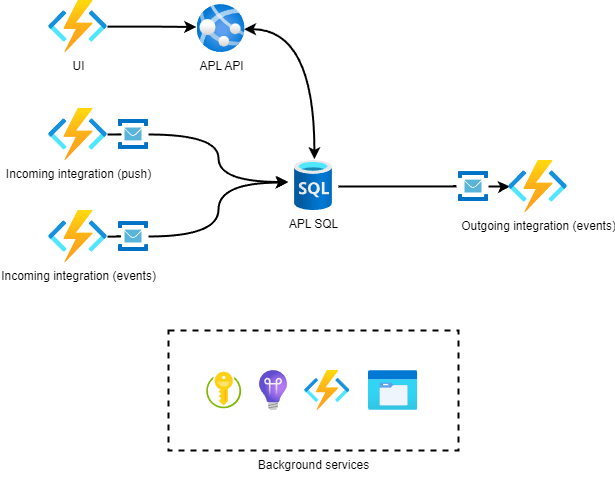
APL is an internal tool for viewing and managing product availability data that is composed of 3 different integrations. This data is then sent downstream, possibly enriched by user activity through the application web UI. Two of the integrations use event-based architecture with Event Grid which is a familiar pattern for many. The third one pushes all their data to us every 2 hours, due to customer demands and limitations.
Azure functions and service bus queues were used extensively in the integration interfaces and with background processing, as well as scheduled tasks. The integrations were probably the most challenging aspect of the project. Pain points were especially authentication, data quality, long end-to-end chain from the original source (SAP) and customer limitations.
1. Data vault pattern can be very useful
As developers, I feel like the first instinct we have when receiving data from integrations that has to be processed and/or reduced is to build some kind of big machine that blurts the processed data into our neat SQL table. This is not automatically a bad idea, but you will probably lose some data in the process and might lose sight of what the original data actually was before processing it.
In our case, the specifications at the beginning of the project were unclear and changed all the time. It was not known what data was going to be used in the system from the massive batches our first integration sent us. That integration was also sending data to a different endpoint of ours. The data would have to be combined with the other data at some point, in some unknown way. We recognized that the other integrations would also have an effect on this critical dataset. Even worse, there were requirements for overriding the values from the UI that would be shown if those overriding values existed. The overriding data would be collected from yet another SQL table.
What worked for us very well was to collect and persist all the data we were getting from the integration before doing anything to alter it. We would then build a SQL view on top that had all the logic of how to present the data to the rest of the system. With a set of data that was probably going to be the "final truth" in a lot of places of the application, it was a good idea in the end to have a centralized place for this information.
This was not a puristic data vault by any definition, but it did serve us perfectly well. I think the biggest point is that by holding on to all the data, we played the situation safe and that worked out. And speaking of holding on to all the data…
2. Store any integration event in blob storage
Storage is cheap, and Azure blob storage is very cheap. We implemented this functionality pretty late in the project and realized that it should have been there almost immediately after we got some data from our first integration. I'm writing about "events" here, but I don't mean just storing Event Grid events. I mean that in addition to those events you should probably save any incoming or outgoing data that is being persisted or requested, before the persisting or sending action is executed.
The reason for this is that debugging any data issue with an integration is infinitely faster if you have immediate access to the exact data available that caused the problem. This is true especially for data that is not easily requested again from the source (for example, behind complex authentication).
It's also useful to store the same data in different containers just for convenience reasons. We had different containers for "by date" and "by ID" that had the same data, just different naming conventions and file structure. These containers that barely cost the customer anything in Azure costs probably saved them thousands in labor costs. A 45-minute debugging session went down to 10 minutes, and there were lots of occasions when something had to be checked this way.
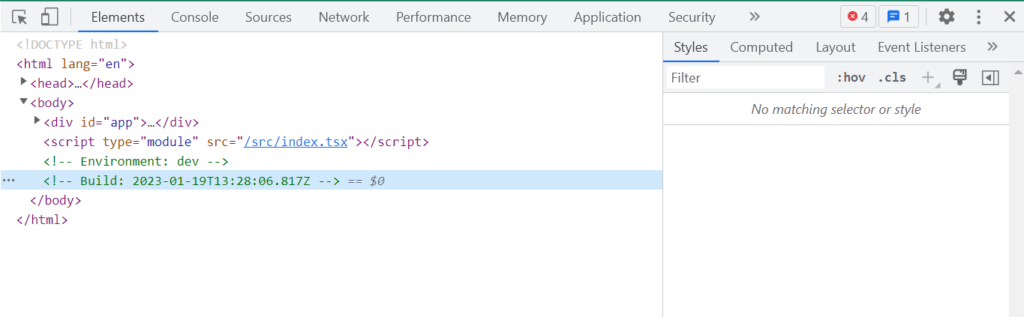
3. Apply a timestamp for your front-end version
In the browser console or as an HTML tag somewhere. It can be surprisingly important information when debugging. This was implemented in the Zure internal code template at the end stretch of this project.
4. Unit test in important locations
It's not a new lesson, but remembering to add unit tests to the critical parts of the application was again an important thing to keep in mind. It's interesting how it goes: When developing the tests it seems like you couldn't even complete the feature without them. Later on they seem useless and a waste of time. Having tests for the integrations in APL was necessary mostly because of the logic changes that came later on, not because of getting things to work in the first place. The tests helped to keep a documentation of the existing logic which already was quite complex.
Integration tests would have been nice. We went with using SQLite instead of a real SQL database, so those would have been difficult to apply. SQLite also had other compatibility issues, but it was very light to work with. It's still difficult to tell which test DB approach would have been the optimal one.
5. Learn more about certificates
We implemented certificate-based authentication in this project in our integrations. The starting point, at least for me, was pretty uncomfortable. I didn't know much about certificates in general, and even less how they should be used with Azure AD. Researching all the things to get everything to work in a pretty tight timeframe was a little stressful.
I recommend learning more about certificates just because even if it's not with Azure AD, there will probably be a time when you will have to work with them. Certificates will not be deprecated for a long time when it comes to authentication, even if there exists something different like managed identities. Learn about general use and format, self-signed certificates vs. CA issued, OAuth2 angle, client certificates pattern. A little studying in advance will help you prepare for the next challenge where certificates are at focus, which will probably be some kind of integration work.
For more information about working with certificates with Azure AD, check out my previous post (also in Zure blog): https://zure.com/blog/azure-ad-securing-integrations-with-oauth2-certificates/
Final thoughts
This project was not the simplest one, but it was still mostly built with blocks familiar to all the developers. The technical success of the project was largely achieved by using tried and true patterns and correcting course whenever we noticed that the solution was heading in the wrong direction, even if the feature or design choice was already built quite far. That rarely happens, and it was made possible by good communication between the developers as well as a healthy amount of allocation to the project per developer.
It's very comforting when a project has an expert group of developers as well as a supporting, committed cast of people with diverse skill sets. It makes you feel safe and trust in the success of the project. This project did that exceptionally, but I'm also glad that I won't have to be too anxious about that missing in the next one when working at Zure. Have a good start to the year 2023.


